Σε αυτήν την ενότητα θα
ασχοληθούμε με τις μεθόδους συμπίεσης που
χρησιμοποιούνται σε εφαρμογές πολυμέσων.
Δεν πρόκειται να επιχειρήσουμε αναλυτική
περιγραφή αυτών, απλά θα δοθούν οι βασικές
αρχές πάνω στις οποίες στηρίζονται.
Γιατί
χρειαζόμαστε συμπίεση
Τα σημερινά αποθηκευτικά
μέσα αδυνατούν να ικανοποιήσουν τις
τεράστιες ανάγκες που επιβάλλουν οι
εφαρμογές πολυμέσων που κάνουν ευρεία
χρήση εικόνων, ήχου και βίντεο. Ένα CD-ROM,
το οποίο έχει χωρητικότητα 650MB,
χωρά 75 λεπτά ασυμπίεστου στερεοφωνικού
ήχου ποιότητας CD
αλλά μόλις 30δευτερόλεπτα
ασυμπίεστης ψηφιακής τηλεόρασης. Ακόμα και
οι μαγνητικοί δίσκοι, που φτάνουν τα 4GB, δεν επαρκούν, αφού μια
ταινία 90 λεπτών απαιτεί γύρω στα 120GB.
Ψηφιοποιώντας μια
φωτογραφία με μια λογική ανάλυση 2000´2000
σημείων, προκύπτουν 4εκατ. εικονοστοιχεία(pixels),
που αντιστοιχούν σε 10ΜΒ αποθηκευτικού
χώρου. Αν αναλογιστούμε ότι ένα νοσοκομείο
πρέπει να μπορεί να διατηρεί και
προσπελαύνει μερικά εκατομμύρια
ακτινογραφίες, καταλαβαίνουμε ότι, όσο
γρήγορα και να αναπτύσσεται η τεχνολογία
των αποθηκευτικών μέσων, χρειάζεται κάτι
ακόμα για να υλοποιηθούν πραγματικές
εφαρμογές πολυμέσων σε ευρεία κλίμακα.
Συμπίεση
με απώλειες και χωρίς απώλειες
Τη λύση σε αυτό το πρόβλημα
έρχεται να δώσει η συμπίεση.
Στόχος της συμπίεσης είναι ο περιορισμός του μεγέθους που
καταλαμβάνει ένα ποσό πληροφορίας εις
βάρος βέβαια της διαθεσιμότητας του, της
υπολογιστικής ισχύος και πολύ συχνά και της
ακρίβειας του περιεχομένου του.
Τα δύο πρώτα πράγματα
που θυσιάζονται κατά την συμπίεση της
πληροφορίας είναι η διαθεσιμότητα της και
ένα ποσό υπολογιστικής ισχύος. Αυτό
σημαίνει, ότι οι διαδικασίες συμπίεσης και
αποσυμπίεσης έχουν υπολογιστικό κόστος,
που μπορεί να είναι τόσο μεγάλο που να
απαιτεί ειδικό υλικό για να γίνει σε
πραγματικό χρόνο. Από την άλλη πλευρά, η
συμπιεσμένη μορφή της πληροφορίας δεν
είναι άμεσα αξιοποιήσιμη. Πρέπει να
προηγηθεί το στάδιο της αποσυμπίεσης για να
αποκτήσει ξανά το σημασιολογικό της
περιεχόμενο. Συνήθως μας απασχολεί η
ταχύτητα αποσυμπίεσης και όχι τόσο αυτή της
συμπίεσης. Στις περισσότερες εφαρμογές η
συμπίεση γίνεται μια φορά στο στάδιο της
κατασκευής και με χρήση ειδικού υλικού, ενώ
η αποσυμπίεση γίνεται από τους χρήστες που
έχουν στην διάθεση τους υπολογιστές
γενικής χρήσης.
Διακρίνουμε δύο
τύπους αλγορίθμων συμπίεσης:
·
Αλγόριθμοι συμπίεσης χωρίς
απώλειες ή αντιστρεπτοί
(lossless
compression)
Αυτό το είδος
αλγορίθμων έχει το ιδιαίτερο
χαρακτηριστικό ότι η διαδικασία συμπίεσης
δεν αλλοιώνει καθόλου την πληροφορία.
Δηλαδή, μετά την αποσυμπίεση, η πληροφορία
επανέρχεται ακριβώς στην μορφή που είχε
πριν. Συνήθως, αυτοί οι αλγόριθμοι
εφαρμόζονται σε περιπτώσεις που δεν
υπάρχει κανένα περιθώριο απωλειών. Για
παράδειγμα, αν η πληροφορία που μεταφέρεται
είναι ένα πρόγραμμα υπολογιστή, ένα και
μόνο αλλοιωμένο bit
μπορεί να είναι αρκετό να καταστήσει το
πρόγραμμα άχρηστο.
·
Αλγόριθμοι συμπίεσης με απώλειες
ή μη αντιστρεπτοί (lossy
compression)
Αν, για
παράδειγμα, η πληροφορία περιγράφει μια
φωτογραφία, είναι δυνατόν να επιτύχουμε
καλύτερη συμπίεση κάνοντας μερικές
υποχωρήσεις όσον αφορά στην πιστότητα του
συμπιεσμένου σήματος. Είναι φανερό ότι σε
τέτοιες περιπτώσεις το σημασιολογικό
περιεχόμενο ουσιαστικά δεν μεταβάλλεται
αλλά υπεισέρχεται η έννοια της μείωσης της
ποιότητας. Το ψηφιακό σήμα ως ακολουθία bits
σαφώς και μεταβάλλεται.
Μια απλοποιημένη
ταξινόμηση των τεχνικών συμπίεσης είναι η
εξής: κωδικοποίηση
εντροπίας (entropy
encoding)
και κωδικοποίηση πηγής (source
encoding).
Η κωδικοποίηση
εντροπίας αναφέρεται σε τεχνικές, οι
οποίες δεν λαμβάνουν υπ’ όψη τους το είδος
της πληροφορίας που πρόκειται να
συμπιεστεί. Με άλλα λόγια, αυτές οι τεχνικές
αντιμετωπίζουν την πληροφορία ως μια απλή
ακολουθία bits.
Γι΄ αυτό το λόγο, η κωδικοποίηση εντροπίας
μπορεί να εφαρμοσθεί ανεξάρτητα από το
είδος της πληροφορίας. Επιπλέον, οι
τεχνικές κωδικοποίησης εντροπίας
προσφέρουν κωδικοποίηση
χωρίς απώλειες.
Ας δούμε ένα
παράδειγμα. Μπορούμε να αντικαθιστούμε
κάθε ακολουθία 10 διαδοχικών μηδενικών που
βρίσκουμε με ένα ειδικό χαρακτήρα
ακολουθούμενο από τον αριθμό 10. Με αυτόν τον
τρόπο, μειώνουμε το μήκος της ακολουθίας
χωρίς να κάνουμε καμία υπόθεση για την
σημασία των μηδενικών, αλλά και χωρίς να
αλλοιώνεται το σήμα.
Οι τεχνικές
κωδικοποίησης εντροπίας διαχωρίζονται σε
δύο βασικές κατηγορίες:
·
Περιορισμός των
επαναλαμβανόμενων ακολουθιών (Suppression
of
repetitive
sequences)
·
Στατιστική
Κωδικοποίηση (Statistical
encoding)
Η διαφορά αυτής
της τεχνικής είναι ότι οι μετασχηματισμοί
τους οποίους υφίστανται το αρχικό σήμα
εξαρτώνται άμεσα από το τύπο του. Για
παράδειγμα, ο λόγος χαρακτηρίζεται από
συχνά διαστήματα σιωπής, που μπορούν να
περιγραφούν με πιο αποτελεσματικό τρόπο.
Δηλαδή, οι μετασχηματισμοί του σήματος
κάνουν χρήση των ιδιαίτερων σημασιολογικών
χαρακτηριστικών που μεταφέρει το σήμα.
Γενικά,
αυτές οι τεχνικές μπορούν να παράγουν
μεγαλύτερα ποσοστά συμπίεσης σε σχέση με
την κωδικοποίηση εντροπίας. Μειονεκτούν
όμως στη σταθερότητα, γιατί το ποσοστό
συμπίεσης που επιτυγχάνουν
διαφοροποιείται ανάλογα με το αντικείμενο
που συμπιέζεται. Πάντως, η κωδικοποίηση
πηγής μπορεί να λειτουργήσει και με
απώλειες και χωρίς απώλειες.
Οι
τεχνικές κωδικοποίησης πηγής διακρίνονται
σε τρεις τύπους:
·
Κωδικοποίηση
μετασχηματισμού (transform
encoding)
·
Διαφορική ή
προβλεπτική κωδικοποίηση (differential
or
predictive
encoding)
·
Διανυσματική
κβαντοποίηση (vector
quantization)
Να
σημειωθεί ότι οι δυο παραπάνω κατηγορίες
κωδικοποίησης δεν αποκλείουν η μια την άλλη.
Υπάρχουν αλγόριθμοι που συνδυάζουν
τεχνικές και των δυο κατηγοριών για να
επιτύχουν καλύτερα αποτελέσματα.
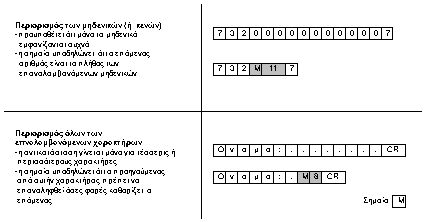
Περιορισμός
των ακολουθιών επαναλαμβανόμενων
χαρακτήρων
Αυτή η μέθοδος κωδικοποίησης
εντροπίας είναι από τις παλαιότερες και πιο
απλές που χρησιμοποιούνται. Η ιδέα είναι
ότι σε μια τυχαία ακολουθία από bits
είναι να πιθανό να εμφανιστούν
κάποια τμήματα που αποτελούνται από κάποιο
επαναλαμβανόμενο χαρακτήρα.
Αυτά τα τμήματα μπορούν να αντικατασταθούν
από το χαρακτήρα, ένα ειδικό χαρακτήρα, που
ονομάζεται σημαία, και το πλήθος των
επαναλήψεων του χαρακτήρα σε αυτά. Η
κωδικοποίηση αυτή έχει την παρακάτω
σημασία: Κάθε φορά που συναντάται η σημαία,
ο χαρακτήρας που προηγείται αυτής πρέπει να
επαναληφθεί όσες φορές υποδεικνύει ο
αριθμός που ακολουθεί τη σημαία.
Σχήμα 4-6. Παραδείγματα
περιορισμού των επαναλαμβανόμενων
χαρακτήρων
Αυτή η
μορφή που περιγράψαμε μπορεί να γίνει πιο
αποδοτική, αν έχουμε συχνά εμφανιζόμενες
ακολουθίες μηδενικών. Σ’ αυτές τις
περιπτώσεις απαιτείται απλώς μια σημαία (που
θα σημαίνει “επαναλαμβανόμενα μηδενικά”)
και ο αριθμός των επαναλήψεων. Και στις δύο
περιπτώσεις, το μήκος των ακολουθιών πρέπει
να είναι τέτοιο, ώστε να υπάρχει ουσιαστικό
όφελος από αυτήν την αντικατάσταση.
Και η στατιστική
κωδικοποίηση είναι μια μέθοδος που
χρησιμοποιείται πολύ συχνά. Η βασική αρχή
αυτής της τεχνικής βρίσκεται στο εντοπισμό
των πιο συχνά εμφανιζόμενων ακολουθιών
χαρακτήρων και στην κωδικοποίηση τους με
λιγότερα bits.
Δηλαδή οι σπάνια εμφανιζόμενες ακολουθίες
θα έχουν μεγαλύτερους κωδικούς, ενώ οι
συχνές μικρότερους.
Είναι
φανερό ότι η μέθοδος απαιτεί την ύπαρξη λεξικού,
όπου αποθηκεύονται οι ακολουθίες που
αντιστοιχούν σε κάθε κωδικό για να μπορεί
να γίνει η αποσυμπίεση. Καθοριστικής
σημασίας για την επίδοση του αλγόριθμου
είναι η στατιστική επεξεργασία των
δεδομένων, για την ανεύρεση των ακολουθιών
που θα κωδικοποιηθούν με μικρούς κωδικούς.
Στην απλούστερη περίπτωση, το λεξικό είναι
σταθερό, ενώ στην πιο σύνθετη το βρίσκουμε
κάθε φορά που γίνεται η συμπίεση κάποιας
ποσότητας δεδομένων.
Η
στατιστική κωδικοποίηση παίρνει δύο μορφές:
αντικατάσταση προτύπων (pattern
substitution)
και κωδικοποίηση Huffman
(Huffman
encoding).
Η μέθοδος της αντικατάστασης
προτύπων χρησιμοποιείται αποκλειστικά
για κείμενα. Συχνά εμφανιζόμενα πρότυπα (ακολουθίες
χαρακτήρων, λέξεις) αντικαθιστώνται με
λίγους χαρακτήρες. Για παράδειγμα, θα
μπορούσαμε να κωδικοποιήσουμε αυτές τις
σημειώσεις αντικαθιστώντας τη λέξη “πολυμέσα”
με τους χαρακτήρες “*π”. Σε
μια τέτοια περίπτωση, το λεξικό
προκύπτει από ανάλυση του κειμένου, ενώ
κάποιες λέξεις είναι εκ των προτέρων γνωστό
ότι θα εμφανιστούν σίγουρα.
Η κωδικοποίηση
Huffman αποτελεί μια γενίκευση τις
στατιστικής κωδικοποίησης. Για κάποιο
ρεύμα
δεδομένων υπολογίζεται η συχνότητα
εμφάνισης κάθε χαρακτήρα. Από αυτήν την
συχνότητα, ο αλγόριθμος του Huffman υπολογίζει το ελάχιστο
μήκος κωδικού που πρέπει να δοθεί σε κάθε
χαρακτήρα και πραγματοποιεί τη βέλτιστη
ανάθεση κωδικών. Αυτοί οι κωδικοί
αποθηκεύονται στο λεξικό.
Η
μέθοδος του Huffman
χρησιμοποιείται στη συμπίεση
ακίνητης και κινούμενης εικόνας. Ανάλογα με
τις λεπτομέρειες τις υλοποίησης, ένα νέο
λεξικό δημιουργείται για κάθε εικόνα ή
ομάδα εικόνων. Στην περίπτωση της
κινούμενης εικόνας, το λεξικό μπορεί να
επαναδημιουργείται για κάθε πλαίσιο ή
σειρά πλαισίων. Σε κάθε περίπτωση, η
διαδικασία συμπίεσης πρέπει να αποθηκεύει
το λεξικό για να είναι δυνατή η αποσυμπίεση.
Η κωδικοποίηση
μετασχηματισμού είναι ο πρώτος τύπος
κωδικοποίησης πηγής που εξετάζουμε. Όπως
έχουμε εξηγήσει, η κωδικοποίηση πηγής
λαμβάνει υπ’ όψη και τις ιδιότητες του
σήματος που πρόκειται να συμπιεστεί. Η
κωδικοποίηση μετασχηματισμού
χρησιμοποιείται συνήθως στη συμπίεση
εικόνων. Η βασική της αρχή είναι η εξής:
Στη
κωδικοποίηση μετασχηματισμού, το σήμα
υφίσταται ένα μαθηματικό μετασχηματισμό
από το αρχικό πεδίο του χρόνου ή του χώρου
σε ένα αφηρημένο πεδίο το οποίο είναι πιο
κατάλληλο για συμπίεση. Αυτή η διαδικασία
είναι αντιστρεπτή, δηλαδή υπάρχει ο
αντίστροφος μετασχηματισμός που θα
επαναφέρει το σήμα στην αρχική του μορφή.
Ένας
τέτοιος μετασχηματισμός είναι ο
μετασχηματισμός Fourier.
Μέσω του μετασχηματισμού Fourier
μια συνάρτηση του χρόνου f(t)
μπορεί να μετασχηματιστεί σε μια g(λ)
στο πεδίο των συχνοτήτων. Η νέα αυτή
συνάρτηση παρέχει το πλάτος (ή συντελεστή) g
των συχνοτήτων λ που απαρτίζουν την αρχική
συνάρτηση. Στην περίπτωση των εικόνων
χρησιμοποιείται μια ειδική μορφή του
μετασχηματισμού Fourier,
o
διακριτός συνημιτονικός
μετασχηματισμός Fourier,
και το σημαντικό σημείο που
εκμεταλλευόμαστε είναι το εξής:
Στη
φασματική (στο πεδίο των συχνοτήτων)
αναπαράσταση των εικόνων, οι συχνότητες
περιγράφουν πόσο γρήγορα μεταβάλλονται τα
χρώματα και η απόλυτη φωτεινότητα.
Εκτός από
τον μετασχηματισμό Fourier
υπάρχουν και άλλοι, όπως οι
μετασχηματισμοί των Hadamar,
Haar
και των Karhunen-Loeve.
Ανάλογα με τις ιδιότητες του τύπου της
πληροφορίας που θέλουμε να συμπιέσουμε,
επιλέγουμε και τον καταλληλότερο
μετασχηματισμού.
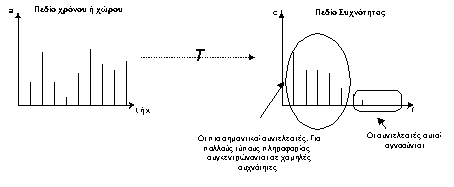
Σχήμα 4-7. Η
βασική αρχή της κωδικοποίησης
μετασχηματισμού
Αφού
επιλεχθεί και εκτελεστεί ο μετασχηματισμός,
βρίσκουμε τους πιο σημαντικούς από τους
συντελεστές και τους περιγράφουμε με
μεγάλη ακρίβεια. Τους λιγότερο σημαντικούς
μπορούμε να τους περιγράψουμε με μικρότερη
ακρίβεια ή και να τους αγνοήσουμε τελείως.
Κάνοντας κάτι τέτοιο η διαδικασία
συμπίεσης έχει απώλειες. Παρ’
όλα αυτά, οι μετασχηματισμοί από μόνοι τους
είναι αντιστρεπτοί.