![]()
![]()
![]()
![]()
Επόμενο:Κεφάλαιο 3o : Αρχιτεκτονική συστημάτων διαμοιραζόμενης μνήμης Πάνω:Κεφάλαιο 2ο: Παραλληλισμός Δεδομένων Πίσω:Προγραμματιστικές Εργασίες
ΑΣΚΗΣΕΙΣ
1. Γράψτε μια σειριακή συνάρτηση που να υπολογίζει και να επιστρέφει το άθροισμα των στοιχείων ενός μονοδιάστατου πίνακα. Γράψτε το κυρίως πρόγραμμα ώστε να εφαρμόζει την συνάρτηση για 4 διαφορετικούς πίνακες. Προσοχή στις συγκρούσεις των καθολικών διαμοιραζόμενων μεταβλητών του προγράμματος.
2. Για να βελτιωθεί η οπτική ποιότητα μιας εικόνας που απεικονίζεται σε ένα διδιάστατο πίνακα εικονοστοιχείων (pixel), εφαρμόζεται ορισμένες φορές ένας αλγόριθμος λείανσης (smoothing). Ένας απλός αλγόριθμος λείανσης αντικαθιστά την τιμή κάθε εικονοστοιχείου με τον μέσο όρο των γειτονικών του εικονοστοιχείων. Κάθε εικονοστοιχείο έχει 8 γείτονες, περιλαμβάνοντας και τους διαγώνιους γείτονες. Ένας άλλος αλγόριθμος αντικαθιστά την τιμή κάθε εικονοστοιχείου με τον μέσο όρο 9 εικονοστοιχείων, περιλαμβάνοντας και το ίδιο το εικονοστοιχείο μαζί με τα 8 γειτονικά. Σε αυτή την άσκηση, πρέπει να γράψετε και να εκτελέσετε ένα παράλληλο πρόγραμμα που να εφαρμόζει αυτό τον αλγόριθμο σε μια εικόνα. Για να απλοποιηθεί το πρόγραμμα, μην τροποποιήσετε τα εικονοστοιχεία που βρίσκονται πάνω στις 4 πλευρές του πίνακα απεικόνισης της εικόνας.
3. Γράψτε ένα παράλληλο πρόγραμμα που αναζητά έναν αριθμό σε ένα διδιάστατο πίνακα. Εκτελέστε το πρόγραμμα με το διαλογικό σύστημα της Multi-Pascal και προσπαθήστε να ελαχιστοποιήσετε τον χρόνο εκτέλεσης, μεταβάλλοντας τον κύκλο ζωής των διεργασιών.
4. Φανταστείτε το παρακάτω κομμάτι ενός προγράμματος:
... FORK x := x+1; FORK y := 23*z; FORK z := a[i]+a[j]; ...
Ανεξάρτητα από τον παραλληλισμό αυτής της πρότασης, έχει βρεθεί ότι ο συνολικός χρόνος εκτέλεσης μπορεί να μειωθεί, με την αφαίρεση του τελεστή FORK άρα και του παραλληλισμού. Ποια είναι η εξήγηση για αυτή τη φαινομενική αντίφαση;
5. Το πρόγραμμα της παράλληλης ταξινόμησης σειράς του διαγράμματος 2.3 δημιουργεί n διεργασίες, μία για κάθε στοιχείο του πίνακα. Ξαναγράψτε το πρόγραμμα για να εκτελείται σε ένα σύστημα διαμοιραζόμενης μνήμης που έχει n/5 επεξεργαστές.
6. Ένα άνυσμα απεικονίζεται σε ένα μονοδιάστατο πίνακα και μια μήτρα σε ένα διδιάστατο πίνακα. Θυμηθείτε ότι το γινόμενο δύο ανυσμάτων A και B, είναι ένας αριθμός C που υπολογίζεται με βάση τον πολλαπλασιασμό αντίστοιχων στοιχείων των A και B και μετά προσθέτοντας όλα τα γινόμενα που προκύπτουν (εσωτερικό γινόμενο). Το γινόμενο μιας μήτρας M με ένα άνυσμα A είναι ένα νέο άνυσμα C. Κάθε στοιχείο του ανύσματος C υπολογίζεται ως εξής:
C[ i ] = εσωτερικό γινόμενο του ανύσματος A με τη γραμμή i της M
Γράψτε ένα παράλληλο πρόγραμμα που να υπολογίζει το γινόμενο μιας μήτρας [20x20] με ένα άνυσμα που περιέχει 20 στοιχεία.
7. Φανταστείτε την παρακάτω έκδοση του προγράμματος παράλληλης ταξινόμησης σειράς όπου η διαδικασία PutinPlace έχει μεταφερθεί στο σώμα του κυρίως προγράμματος ως τμήμα ενός βρόχου FORALL:
PROGRAM NewRankSort;
CONST n=100;
VAR values, final: ARRAY [1..n] OF INTEGER;
i: INTEGER;
src, testval, j, rank: INTEGER;
BEGIN
FOR i := 1 to n Do
Readln(values[i] ); (* Αρχικοποιεί τις τιμές που θα ταξινομηθούν *)
FORALL src := 1 TO n DO
BEGIN
testval := values[src];
j := src; (* το j θα μετακινηθεί σειριακά σε όλο τον πίνακα *)
rank := 0;
REPEAT
j := j MOD n+1;
IF testval >= values[j] THEN rank := rank + 1;
UNTIL j=src;
final[rank] := testval; (*τοποθετεί τις τιμές στη *) (* ταξινομημένη θέση *)
END;
END.
α) Το πρόγραμμα αντιμετωπίζει ένα σοβαρό πρόβλημα και δεν θα παράγει τα σωστά αποτελέσματα. Εξηγείστε τη φύση του προβλήματος.
β) Υποδείξτε ορισμένες μικρές τροποποιήσεις που θα διορθώσουν το πρόβλημα και θα
επιτρέψουν στο πρόγραμμα να λειτουργήσει σωστά.
8. Το πρόγραμμα παράλληλης ταξινόμησης σειράς δεν θα λειτουργήσει σωστά εάν η λίστα που είναι προς ταξινόμηση περιέχει όμοιες τιμές.
α) Εξηγείστε τη φύση του σφάλματος που προκύπτει εξαιτίας των όμοιων τιμών που
υπάρχουν στη λίστα.
β) Υποδείξτε μια μικρή τροποποίηση που θα διορθώσει το πρόβλημα του προγράμματος.
9. Στο πρόγραμμα παράλληλου πολλαπλασιασμού μητρών που παρουσιάζεται στο κεφάλαιο, δημιουργούνται n2 διεργασίες. Ξαναγράψτε το πρόγραμμα για ένα σύστημα διαμοιραζόμενης μνήμης που διαθέτει μόνο n επεξεργαστές. Προσέξτε ιδιαίτερα τη χρήση των διαμοιραζόμενων και τοπικών μεταβλητών ώστε να αποφευχθούν οι παρεμβολές ανάμεσα στις παράλληλες διεργασίες.
10. Φανταστείτε την παρακάτω πρόταση FORALL:
FORALL i := 1 TO 200 GROUPING size DO A[i] := 10*A[i];
Χρησιμοποιείστε το διαλογικό σύστημα της Multi-Pascal για να υπολογίσετε την επιτάχυνση που επιτυγχάνεται από αυτή την πρόταση καθώς η μεταβλητή size παίρνει τις τιμές από 1 έως 25. Ποιο είναι το άριστο μέγεθος ομάδος που μεγιστοποιεί την επιτάχυνση; Εξηγείστε τους λόγους του γενικού προτύπου αυτής της απόκλισης. Ποιος είναι ο λόγος της αύξησης στην αρχή και ποιο ο λόγος της μείωσης στο τέλος;
11. Ο σειριακός χρόνος εκτέλεσης της εντολής FORALL ορίζεται ως ο χρόνος που χρειάζεται για να εκτελεστεί η ίδια πρόταση με το FORALL αφού αντικατασταθεί από το FOR. Η επιτάχυνση της δήλωσης FORALL παράγεται από τη διαίρεση του χρόνου εκτέλεσης της προς το χρόνο σειριακής εκτέλεσης. Φανταστείτε μια πρόταση εντολής FORALL που δημιουργεί n παράλληλες διεργασίες. Το μέγεθος των διεργασιών είναι τέτοιο ώστε να έχουν χρόνο εκτέλεσης 10 φορές μεγαλύτερο από το χρόνο σειριακής εκτέλεσης. Διατυπώστε μια αλγεβρική παράσταση ως προς n που υπολογίζει τη μέγιστη δυνατή επιτάχυνση της πρότασης FORALL που εκτελείται σε ένα παράλληλο σύστημα με p επεξεργαστές. Διαλέξτε για το σκοπό αυτό, ένα μέγεθος ομάδος για τη FORALL που να μεγιστοποιεί την επιτάχυνση.
12. Θεωρείστε το παρακάτω τμήμα προγράμματος:
PROGRAM Sample;
VAR a,b: INTEGER;
BEGIN
a := 4;
b := 2;
VAR t,a NTEGER;
BEGIN
a := 7;
t := 10;
b := t+5;
END;
Writeln(a,b);
END.
Ποιες θα είναι οι τελικές τιμές των μεταβλητών a και b που θα εμφανισθούν στο τέλος; Εξηγείστε τους λόγους της απάντησης σας.
13. Θεωρείστε την παρακάτω πρόταση FORALL που παράγει τον πίνακα C που αποτελεί το άθροισμα των πινάκων Α και Β:
FORALL i := 1 TO 50 DO C[i] := A[i]+B[i];
Σε μια προσπάθεια να παραχθεί μια παρόμοια πρόταση με τη βοήθεια της FORK, χρησιμοποιείται ο παρακάτω βρόχος FOR:
FOR i := 1 TO 50 DO
FORK C[i] := A[i]+B[i];
Ωστόσο, όταν η πρόταση εκτελείται, παράγεται ένα εσφαλμένο αποτέλεσμα στον πίνακα C. Εξηγείστε γιατί παράγεται λανθασμένο αποτέλεσμα.
14. (α) Σε αυτό το πρόβλημα πρέπει να γράψετε ένα παράλληλο πρόγραμμα που θα εκτελεί αναζήτηση σε μια συνδεδεμένη λίστα για μια δοθείσα τιμή. Κάθε μονάδα δεδομένων της συνδεδεμένης λίστας είναι ένας πίνακας πραγματικών τιμών. Το πρόγραμμα θα πρέπει να δημιουργεί παράλληλες διεργασίες, που η κάθε μια θα κάνει αναζήτηση σε ένα διαφορετικό πίνακα. Οι παρακάτω τύποι δηλώσεων πρέπει να χρησιμοποιηθούν στην αρχή του προγράμματος καθώς επίσης και η διαδικασία Search. Μην δώσετε προσοχή στην αρχικοποίηση της λίστας.
PROGRAM SearchList;
TYPE arraytype = ARRAY [1..100] OF REAL;
pnttype = ^itemtype;
itemtype = RECORD
data: arraytype;
next: pnttype;
END;
VAR found: BOOLEAN;
listhead: pnttype;
PROCEDURE Search(inarray: arraytype);
VAR i : INTEGER;
BEGIN
FOR i := 1 TO 100 DO
IF inarray[i] = value THEN found := TRUE;
END;
(β) Θα μπορέσει το πρόγραμμα να πετύχει μια καλή επιτάχυνση για μια λίστα με 10 στοιχεία;
15. Θεωρείστε το πρόγραμμα του κεφαλαίου που χρησιμοποιεί τον τελεστή FORK για να δημιουργήσει παράλληλες διεργασίες που εφαρμόζουν μια διαδικασία σε κάθε στοιχείο μιας συνδεδεμένης λίστας. Ξαναγράψτε το πρόγραμμα χρησιμοποιώντας αυτή τη φορά μια πρόταση FORALL για τη διεργασία των διεργασιών αντί του τελεστή FORK. Αυτό θα απαιτήσει μια μικρή αναδιοργάνωση του προγράμματος και τη προσθήκη ορισμένων νέων μεταβλητών. Προσπαθήστε να ελαχιστοποιήσετε τις αλλαγές που χρειάζεται το νέο πρόγραμμα.
16. Η παρούσα άσκηση παρέχει εξάσκηση πάνω στην εφαρμογή των κανόνων εμβέλειας των μετρητών των προτάσεων FORALL (βλέπε παράγραφο 2.5.2). Δώστε το ακριβές αποτέλεσμα καθενός από τα 3 παρακάτω προγράμματα:
PROGRAM Test1; VAR i: integer; BEGIN i := 25; FORALL i := 1 TO 10 DO WRITELN(i); WRITELN(i); END. PROGRAM Test2; VAR i: INTEGER; PROCEDURE Print; BEGIN Writeln(i); END; BEGIN i := 25; FORALL i := 1 TO 10 DO Print; END. PROGRAM Test3; VAR i: INTEGER; PROCEDURE Print(val: integer); BEGIN Writeln(val); END; BEGIN i := 25; FORALL i := 1 TO 10 DO Print(i); END.
17. Η παρακάτω πρόταση υπολογίζει το άθροισμα των στοιχείων ενός πίνακα Α:
OR i := 1 TO n DO sum := sum + A[i];
Στην προσπάθεια να υπολογιστεί το άθροισμα παράλληλα, δίδεται η παρακάτω πρόταση:
FORALL i := 1 TO n DO sum := sum + A[i];
Εξηγείστε γιατί η πρόταση FORALL παράγει λανθασμένο αποτέλεσμα για το άθροισμα.
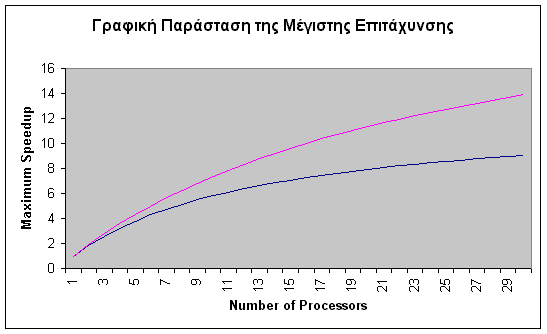
18. Για ένα συγκεκριμένο αλγόριθμο, υποθέστε ότι 8% του κώδικα του είναι αμιγώς σειριακός που δεν μπορεί να μετατραπεί σε παράλληλο κώδικα. Χρησιμοποιήστε το νόμο του Amdahl για να σχεδιάσετε ένα γράφημα της μέγιστης επιτάχυνσης του αλγόριθμου καθώς ο αριθμός των επεξεργαστών παίρνει τιμές από 1 έως 30. Στο ίδιο γράφημα, σχεδιάστε την καμπύλη μέγιστης επιτάχυνσης για ένα αλγόριθμο που περιέχει μόνο 4% σειριακό κώδικα.
19. Το γράφημα του σχεδιαγράμματος 2.7 υποθέτει ότι το σύστημα κατανεμημένης μνήμης διαθέτει 100 επεξεργαστές. Υπολογίστε και σχεδιάστε το γράφημα ξανά, υποθέτοντας ότι το σύστημα έχει μόνο 50 επεξεργαστές.
20. Φανταστείτε ένα σειριακό πρόγραμμα του οποίου το συνολικό πλήθος υπολογισμών είναι O(n3). Υποθέστε ότι στην παράλληλη έκδοση του προγράμματος, η αρχικοποίηση πρέπει να γίνει σειριακά και επομένως το σύνολο υπολογισμών είναι O(n). Ωστόσο, το υπόλοιπο του προγράμματος λειτουργεί παράλληλα. Χρησιμοποιήστε το νόμο του Amdahl για να διατυπώστε μια γενική αλγεβρική παράσταση που υπολογίζει τη μέγιστη επιτάχυνση του προγράμματος σε ένα σύστημα κατανεμημένης μνήμης με p επεξεργαστές.
21. Υπό το πρίσμα του νόμου του Amdahl, εξηγείστε γιατί είναι σημαντικό σε συστήματα κατανεμημένης μνήμης να έχουν ειδικά σχεδιασμένα, υψηλού εύρους ζώνης συστήματα εισόδου-εξόδου ( I / O ).
ΠΡΟΤΕΙΝΟΜΕΝΕΣ ΛΥΣΕΙΣ
1.
Program K2A1;
var pin:array [1..4,1..5] of integer;
i,j:integer;
procedure calculate(pnt:integer);
var sum,k:integer;
begin
sum:=0;
for k:=1 to 5 do
sum:=sum+pin[pnt,k];
writeln(sum);
end
begin
for i:=1 to 4 do
for j:=1 to 5 do
readln(pin[i,j]);
forall i:=1 to 4 do
calculate(i);
end.
2.
Program K2A2;
constn=768;
m=1024;
var pin:array [1..n,1..m] of integer;
i,j:integer;
procedure smooth(t,s:integer);
begin
pin[t,s]:=[pin[t-1,s-1]+pin[t-1,s]+pin[t-1,s+1]+pin[t,s-1]+pin[t,s]+pin[t,s+1]+pin[t+1,s-1]+pin[t+1,s]+pin[t+1,s+1]]/9;
end;
begin
for i:=1to n do
for j:=1 to m do
pin[i,j]:=1;
forall i:=2to n-1 do
forall j:=2 to m-1 do
smooth(i,j);
end.
3.
ProgramK2A3;
Const n=6;
Var A:array[1..n,1..n] of integer;
i,j,Num:integer;
Found:boolean;
ProcedureSearch(element:integer);
Begin
if element=Num then Found:=true;
End;
Begin
Found:=false;
write('Δώσε τον αριθμό αναζήτησης')
readln(Num);
for i:=1 to n do
for j:=1 to n do
readln(a[i,j]);
forall i:=1 to n do
forall j:=1 to n grouping 2 do
Search(a[i,j]);
if found then writeln('Ο αριθμός βρέθηκε');
else writeln('Ο αριθμός δεν βρέθηκε');
End.
4.Η εξήγηση είναι ότι για να δημιουργηθούν αυτές οι τρείς διεργασίες και να ανατεθούν σε επεξεργαστές χρειάζονται χρόνο που λόγω του μικρού του μεγέθους είναι αχρείαστο, ενώ όταν γίνονται μόνο από τη διεργασία γονέα είναι πιο γρήγορα. Επίσης πέζει ρόλο αν βρίσκονταν προς το τέλος του προγράμματος καθώς στην εντολή FORK η διεργασία γονέας περιμένει να τελειώσουν οι θυγατρικές διεργασίες για να τερματίσει.
5.
Program K2A5;
CONST n=10;
var values,final:array [1..n] of integer;
i:integer;
procedure putinplace(src:integer);
var testval,j,rank:integer;
begin
testval:=values[src];
j:=src;
rank:=0;
repeat
j:=j MOD n+1;
if testval >= values[j] then rank:=rank+1;
until j=src;
final[rank]:=testval;
end;
begin
for i:=1 to n do
index[i]:=0;
for i:=1 to n do
readln(values[i]);
forall i:=1to n grouping 5 do
putinplace(i);
end.
6.
Program K2A6;
CONST n=20;
var matrix:array [1..n,1..n] of integer;
vector,c:array [1..n] of integer;
i:integer;
procedure multiply(i:integer);
var j:integer;
begin
for k:=1 to n do
c[i]:=c[i]+vector[k]*matrix[i,k];
end;
begin
forall i:=1 to n do
multiply(i);
end.
8.
Program K2A8;
CONST n=8;
var values,final:array [1..n] of integer;
i: integer;
procedure putinplace(src:integer);
var testval,j,rank,sum:integer;
begin
testval:=values[src];
j:=src;
rank:=0;
sum:=0;
repeat
j:=j MOD n+1;
if testval >= values[j] then rank:=rank+1;
if testval = values[j] then sum:=sum+1;
until j=src;
repeat
final[rank-sum+1]:=testval;
sum:=sum-1;
until sum=0;
end;
begin
for i:=1 to n do
readln(values[i]);
forall i:=1 to n do
putinplace(i);
for i:=1 to n do
writeln(final[i],values[i]);
end.
10. Ο συνολικός αριθμός των διεργασιών παιδιών που δημιουργούνται είναι n/size. Ο συνολικός χρόνος δημιουργίας όλων των διεργασιών είναι επομένως cn/size. Επομένως ο χρόνος εκτέλεσης για τη FORALL έχει ως εξής :
cn/size+sizeT.
Για να ελαχιστοποιηθεί ο χρόνος εκτέλεσης σε σχέση με το size, απλά παίρνουμε την πρώτη παράγωγο ως προς size και τη θέτουμε ίση με το 0. Το αποτέλεσμα είναι το ακόλουθο:
Στο πρόβλημά μας το βέλτιστο μέγεθος ομάδας είναι size=12.
12. Οι τελικές μεταβλητές των τιμών θα είναι 4 και 15 γιατι το a συμπεριλαμβάνεται στην ομάδα εντολών που αρχίζει με το var ενώ το b όχι.
13. Το αποτέλεσμα είναι λανθασμένο επειδή στην περίπτωση του FORK αφού δημιουργηθούν και οι n διεργασίες παιδιά ο βρόχος for θα σταματήσει να εκτελείται και η εκτέλεση της κύριας διεργασίας θα συνεχίσει, ενώ στην περίπτωση του FORALL η διεργασία γονέας περιμένει όλα τα παιδιά να τερματίσουν.
17. Ο παράλληλος υπολογισμός δεν μπορεί να επιτευχθεί με την μετατροπή του εσωτερικού βρόχου FOR σε εντολή FORALL. Οι επαναλήψεις του εσωτερικού βρόχου χρησιμοποιούν τη μεταβλητή sum για να συσσωρεύσουν το άθροισμα: η μεταβλητή sum διαβάζει και γράφει σε κάθε επανάληψη του βρόχου. Επομένως, αυτές οι σειριακές επαναλήψεις δεν μπορόυν απλά να μοιραστούν σε διαφορετικούς επεξεργαστές που θα εκτελούνται παράλληλα. Αν γινόταν αυτό τότε οι επεξεργαστές θα προσπαθούσαν να διαβάσουν και να μεταβάλλουν την τιμή της sum, γεγονός που θα προκαλούσε παρεμβολές και θα παρήγαγε λανθασμένα αποτελέσματα.
18. Για να σχεδιάσουμε το γράφημα θα χρησιμοποιήσουμε τον νόμο του Amdahl.
| Αριθμός Επεξεργαστών | Μέγιστη Επιτάχυνση(f=0.08) | Μέγιστη Επιτάχυνση(f=0.04) |
| 1 | 1 | 1 |
| 2 | 1,851851852 | 1,923076923 |
| 3 | 2,586206897 | 2,777777778 |
| 4 | 3,225806452 | 3,571428571 |
| 5 | 3,787878788 | 4,310344828 |
| 6 | 4,285714286 | 5 |
| 7 | 4,72972973 | 5,64516129 |
| 8 | 5,128205128 | 6,25 |
| 9 | 5,487804878 | 6,818181818 |
| 10 | 5,813953488 | 7,352941176 |
| 11 | 6,111111111 | 7,857142857 |
| 12 | 6,382978723 | 8,333333333 |
| 13 | 6,632653061 | 8,783783784 |
| 14 | 6,862745098 | 9,210526316 |
| 15 | 7,075471698 | 9,615384615 |
| 16 | 7,272727273 | 10 |
| 17 | 7,456140351 | 10,36585366 |
| 18 | 7,627118644 | 10,71428571 |
| 19 | 7,786885246 | 11,04651163 |
| 20 | 7,936507937 | 11,36363636 |
| 21 | 8,076923077 | 11,66666667 |
| 22 | 8,208955224 | 11,95652174 |
| 23 | 8,333333333 | 12,23404255 |
| 24 | 8,450704225 | 12,5 |
| 25 | 8,561643836 | 12,75510204 |
| 26 | 8,666666667 | 13 |
| 27 | 8,766233766 | 13,23529412 |
| 28 | 8,860759494 | 13,46153846 |
| 29 | 8,950617284 | 13,67924528 |
| 30 | 9,036144578 | 13,88888889 |
![]()
![]()
![]()
![]()
Επόμενο:Κεφάλαιο 3o : Αρχιτεκτονική συστημάτων διαμοιραζόμενης μνήμης Πάνω:Κεφάλαιο 2ο: Παραλληλισμός Δεδομένων Πίσω:Προγραμματιστικές Εργασίες