Εισαγωγή
στη Παράλληλη Επεξεργασία
Η εισαγωγή
αυτή είναι βασισμένη στο tutorial
"Introduction to Parallel Computing" του Blaise
Barney, Lawrence Livermore άςLaboratory, USA. Επίσης
έχει προστεθεί υλικό από το βιβλίο
του A.S. Tanenbaum "Structured Computer Organization",
τη Wikipedia, καθώς και από αρκετές πηγές
του Διαδικτύου. Μετάφραση και
προσαρμογή: Κ.Γ. Μαργαρίτης, Εργαστήριο
Παράλληλης Κατανεμημένης Επεξεργασίας,
Τμήμα Εφαρμοσμένης Πληροφορικής,
Πανεπιστήμιο Μακεδονίας.
|
|
Περιεχόμενα
Περίληψη
Επισκόπηση
'Εννοιες
και Ορολογία
Αρχιτεκτονικές
Παράλληλων Υπολογιστών
Υποστήριξη
Παράλληλου Προγραμματισμού
Μοντέλα
Παράλληλου Προγραμματισμού
Ανάπτυξη
Παράλληλων Προγραμμάτων
Σχεδιασμός
Παράλληλων Προγραμμάτων
Απόδοση
Παράλληλων Προγραμμάτων
Παραδείγματα
Παράλληλης Επεξεργασίας
Αναφορές και Περισσότερες
Πληροφορίες
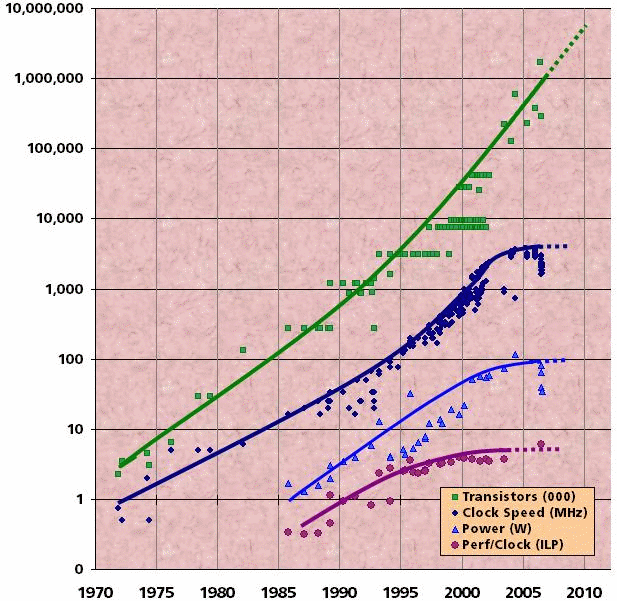
Αυτή η εισαγωγική παρουσίαση καλύπτει
τα βασικά της παράλληλης επεξεργασίας.
Αρχίζει με μια σύντομη επισκόπιση,
ορισμένες βασικές έννοιες και ορολογία,
και συνεχίζει με τα θέματα των παράλληλων
αρχιτεκτονικών και των μοντέλων
παράλληλου προγραμματισμού. Ακολουθεί
μια συζήτηση για ζητήματα σχεδιασμού
παραλλήλων προγραμμάτων. Η τελευταία
ενότητα εξετάζει μερικά παραδείγματα
παράλληλης επεξεργασίας.
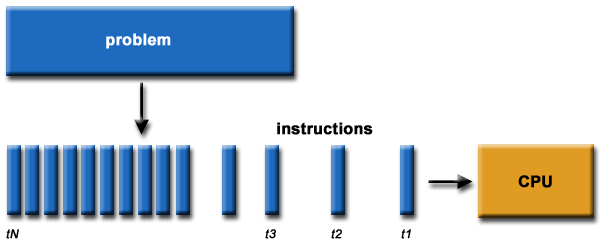
Τι είναι Παράλληλη Επεξεργασία;
Παραδοσιακά, το
λογισμικό γράφεται με στόχο την
ακολουθιακή (σειραική) εκτέλεση:
Ο υπολογιστής
θεωρείται οτι έχει μια Κεντρική Μονάδα
Επεξεργασίας (CPU);
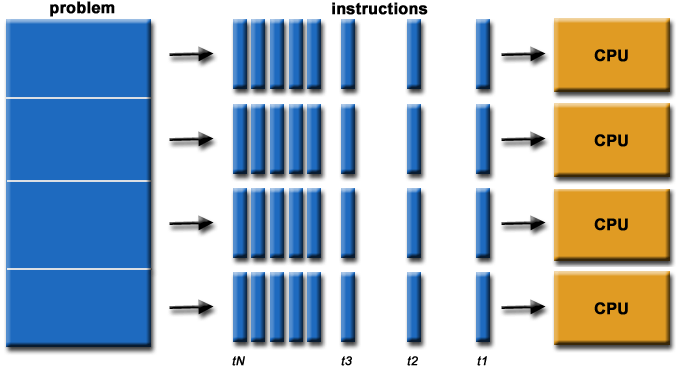
Το πρόβλημα (problem)
επιλύεται με την εκτέλεση μιας
σειράς (ακολουθίας) εντολών (instructions).
Οι εντολές προυποθέτουν
την ολοκλήρωση των προηγούμενων
εντολών.
Κάθε χρονική στιγμή (t1, t2, t3, ...,
tN) εκτελείται μια εντολή.
Στην απλούστερη
μορφή της, η παράλληλη επεξεργασία
είναι η ταυτόχρονη χρήση πολλαπλών
υπολογιστικών πόρων για την επίλυση
ενός προβλήματος.
Ο υπολογιστής
θεωρείται οτι διαθέτει πολλαπλές CPUs
Το πρόβλημα διασπάται
σε διακριτά τμήματα (εργασίες, tasks) που
μπορούν να επιλυθούν ταυτόχρονα.
Κάθε τμήμα επιλύεται
με την εκτέλεση μιας σειράς (ακολουθίας)
εντολών.
Οι εντολές κάθε
τμήματος εκτελούνται ταυτόχρονα σε
διαφορετικές CPUs.
Για τις εντολές κάθε τμήματος
ισχύουν οι περιορισμοί της ακολουθιακής
εκτέλεσης.
Οι υπολογιστικοί
πόροι μπορεί να είναι:
Ένας υπολογιστής
με πολλές CPUs (ή μια CPU με πολλούς πυρήνες
-cores) ή μια CPU με πολλές ALUs. Η σύνδεση
μεταξύ των CPUS ή ALUs καθώς και με τη
κεντρική μνήμη επιτυγχάνεται μέσω
είτε εξειδικευμένου δικτύου διασύνδεσης
ή τυπικού διαύλου.
Πολλοί υπολογιστές
συνδεδεμένοι είτε σε συστοιχίες μέσω
εξειδικευμένης διασύνδεσης υψηλής
απόδοσης και κοινά προσπελάσιμους
δίσκους, ή σε τυπικό τοπικό δίκτυο ή
ακόμη και μέσω διαδικτύου.
Συνδυασμός των δύο παραπάνω
καταστάσεων (πχ υπολογιστές πολλαπλών
πυρήνων σε τοπικό δίκτυο).
Το υπολογιστικό
πρόβλημα συνήθως παρουσιάζει τα παρακάτω
χαρακτηριστικά:
Μπορεί να τεμαχιστεί
σε διακριτά τμήματα - υποπροβλήματα-
που μπορούν να επιλυθούν - εκτελεστούν
- ταυτόχρονα.
Η επίλυση του προβλήματος με τη
χρήση πολλαπλών υπολογιστικών πόρων
είναι αποδοτικότερη από ότι σε απλό
υπολογιστή (αύξηση της ταχύτητας
εκτέλεσης-speedup, αύξηση του μεγέθους
του προβλήματος-scaleup).
Η παράλληλη επεξεργασία
αποτελεί μια εξέλιξη της ακολουθιακής
επεξεργασίας που προσπαθεί να μιμηθεί
αυτό που σχεδόν πάντα συμβαίνει στο
φυσικό κόσμο: πολλά σύνθετα,
αλληλοσχετιζόμενα γεγονότα συμβαίνουν
ταυτόχρονα, το καθένα με τη δική του
εσωτερική ακολοθουθία συμβάντων, και
με καποιας μορφής επικοινωνία ή
συγχρονισμό μεταξύ των γεγονότων.
Μερικά παραδείγματα:
Τροχιές πλανητών,
αστεριών ή γαλαξιών
Μετεωρολογικά
φαινόμενα, θαλάσσια ρεύματα
Κίνηση τεκτονικών
πλακώ
Κυκλοφορία οχημάτων
σε μια πόλη
Γραμμή παραγωγής
σε ένα εργοστάσιο
Ημερήσια δραστηριότητα
σε μια επιχείριση
Οικοδόμηση ενός
τεχνικού έργου
Εξυπηρέτηση μιας παραγγελίας σε
ένα κατάστημα.
Παραδοσιακά, η
παράλληλη επεξεργασία θεωρείται ως
εξειδικευμένη τεχνική με βασικό σκοπό
την αριθμητική επίλυση σύνθετων
προβλημάτων επιστήμης και μηχανικής,
όπως:
Πρόβλεψη του καιρού,
μακροπρόθεσμα κλιματικά μοντέλα
Σύνθετες χημικές
και πυρηνικές αντιδράσεις
Αστρονομία και
υπολογιστική φυσική
Γονιδιωματική,
υπολογιστική βιολογία
Γεωλογία, σεισμολογία
Υπολογιστική
ρευστοδυναμική
Μηχανική - από
νανοεξαρτήματα έως αεροπλάνα
Σύνθετα ηλεκτρικά
και ηλεκτρονικά κυκλώματα
Κατασκευαστικές
διεργασίες
Τεχνητή όραση, επεξεργασία φυσικής
γλώσσας.
Σήμερα, οι επιχειρηματικές
και οικονομικές εφαρμογές αποδεικνύονται
εξ'ισου σημαντικές ή και σημαντικότερες
από τις εφαρμογές επιστήμης και
μηχανικής. Αυτές οι εφαρμογές απαιτούν
την σύνθετες επεξεργασίες μεγάλων
όγκων δεδομένων. Ορισμένα παραδείγματα:
Παράλληλες βάσεις
δεδομένων, εξόρυξη δεδομένων
Αναζήτηση κοιτασμάτων
πετρελαίου και φυσικού αερίου
Μηχανές αναζήτησης
ιστού, διακομιστές και υπηρεσίες ιστού
Ιατρική διάγνωση
με τη βοήθεια υπολογιστή
Χρημαοτοικονομική
και τραπεζική πραγματικού χρόνου
Γραφικά και εικονική
πραγματικότητα
Video, παιγνίδια,
ψηφιακά μέσα
Συστήματα ειδικού
σκοπού, πραγματικού χρόνου
Συνεργατικά
περιβάλλοντα
Συμπερασματικά, αυτό που προσπαθούμε
κατά βάση να πετύχουμε με τη παράλληλη
επεξεργασία είναι να κερδίσουμε χρόνο
ή/και να επεξεργαστούμε μεγαλύτερο
μέγεθος δεδομένων. Το υλικό γίνεται
συνεχώς φθηνότερο και ισχυρότερο, το
λογισμικό είναι γενικά δημόσια
διαθέσιμο και βελτιώνεται συνεχώς, ο
όγκος των δεδομένων αυξάνεται με
αλματώδεις ρυθμούς και λόγω διαδικτύου,
ο διαθέσμιος χρόνος μας παραμένει
ίδιος. Η παράλληλη επεξεργασία προσπαθεί
να εκμεταλλευτεί όσο γίνεται πιο
αποδοτικά το άφθονο υλικό, έτσι ώστε
με τη βοήθεια ειδικού λογισμικού να
επιτύχει μέγιστη επεξεργασία δεδομένων
στον ελάχιστο χρόνο.
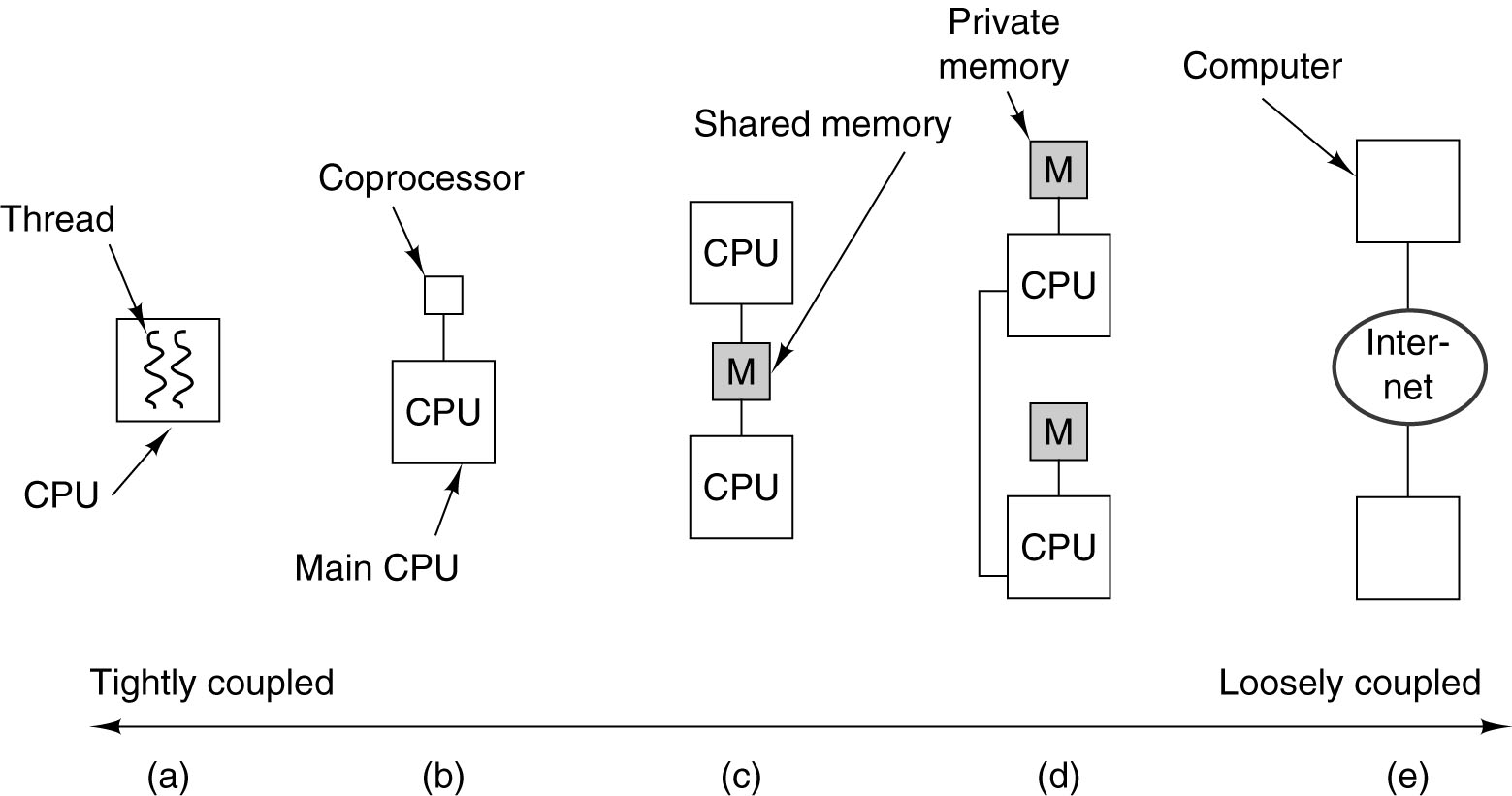
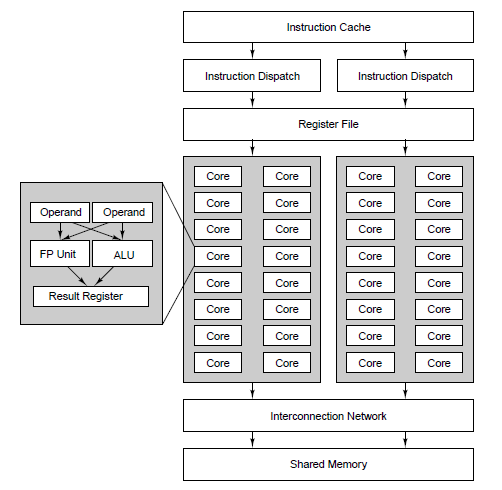
Στα σύγχρονα υπολογιστικά συστήματα
συναντούμε πολλαπλά επίπεδα παραλληλισμού.
Όσο "χαμηλότερο" είναι το επίπεδο
προσέγγισης τόσο τα υπολογιστικά
συστήματα είναι πιο στενά συνδεδεμένα
(tightly coupled) ο δε παραλληλισμός που
εφαρμόζεται είναι πιο λεπτομερής
(fine-grain). Οι υπολογιστικές μονάδες
είναι απλές και πολλές, ενώ η επιοινωνία
ταχύτατη. Αντίστοιχα, στα "υψηλά"
επίπεδα τα συστήματα είναι χαλαρά
συνδεδεμένα (loosely coupled) και ο
παραλληλισμός αδρομερής (coarse-grain).
Οι υπολογιστικές μονάδες είναι ισχυρές
και σχετικά λίγες ενώ η επικοινωνία
σχετικά αργή.
Επίπεδο Δεδομένων (Bit Level
Parallelism): ταυτόχρονη εκτέλεση πράξεων
σε ομοειδή δεδομένα, σε ένα επεξεργαστή
ή και σε συνεπεξεργαστές ειδικού σκοπού
(πχ bit-level παραλληλισμός, λειτουργίες
επεξεργασίας γραφικών, FPGAs, ASICs).
Επίπεδο Εντολής (Instruction Level
Parallelism, ILP): ταυτόχρονη εκτέλεση
εντολών ενός προγράμματο (κρυφή μνήμη,
προ-προσκόμιση, διοχέτευση εντολών
και πράξεων, υπερβαθμωτή εκτέλεση,
πρόβλεψη διακλάδωσης)
Επίπεδο Λειτουργιών (Μultitasking):
ταυτόχρονη εκτέλεση λειτουργιών
(διεργασιών) σε ένα υπολογιστή (πχ χρήση
co-processors, DMA, I/O, κάρτες γραφικών) υπό
τον έλεγχο του λειτουργικού συστήματος
(b).
- Η
Συντρέχουσα (Concurrent) Επεξεργασία
δίνει έμφαση στο διαμοιρασμό ενός ή
περιορισμένων πόρων μεταξύ πολλών
ανεξάρτητων εργασιών που εκτελούνται
ταυτόχρονα. Οι εργασίες είναι συνήθως
σχετικά λίγες και ανόμοιες, και η
επικοινωία μεταξύ τους είναι
μη-προκαθορισμένη (μη-ντετερμινιστική)
και βασίζεται σε συμβάντα (events).
Χαρακτηριστικό πεδίο η ανάπτυξη
λειτουργικών συστημάτων και
πολυνηματικών εφαρμογών σε ένα
υπολογιστή.
-
-
Η Παράλληλη
(Parallel) Επεξεργασία δίνει έμφαση
στην ταυτόχρονη εκτέλεση πολλών
αλληλοεξαρτώμενων εργασιών σε πολλούς
όμοιους πόρους για την επίλυση ενός
προβλήματος. Οι εργασίες είναι συνήθως
σχετικά πολλές, σχετικά όμοιες μεταξύ
τους, και η επικοινωνία ακολουθεί
συνήθως κάποιο προκαθορισμένο ή
κανονικό πρότυπο. Χαρακτηριστικό
πεδίο η ανάπτυξη επιστημονικών και
βιομηχανικών εφαρμογών για την
επεξεργασία πολλών δεδομένων /
εκτέλεση πολλών υπολογισμών.
-
-
Η Κατανεμημένη
(Distributed) Επεξεργασία
δίνει έμφαση στην επικοινωνία πολλών
ανεξάρτητων και ανόμοιων διεργασιών
που εκτελούνται ταυτόχρονα σε
ξεχωριστά σύνολα πόρων και όπου η
επικοινωνία είναι μη-ντετερμινιστική,
ίσως αναξιόπιστη και προκαλεί
σημαντική επιβάρυνση. Χαρακτηριστικό
πεδίο η ανάπτυξη διαδικτυακών
εφαρμογών μεγάλης κλίμακας, με χρήση
πολλαπλών εξειδικευμένων διακομιστών
ή και ομότιμης τεχνολογίας.
-
-
Υπάρχουν σημαντικές αλληλεπικαλύψεις
αλλά και διαφορές. Σταδιακά όμως
τα τρία μοντέλα υπολογισμού οδηγούνται
σε σύγκλιση, όπως αυτό γίνεται φανερό
στις τεχνολογίες Πλέγματος (Grid) και
Νέφους (Cloud).
Ο παραλληλισμός επηρεάζει το σύνολο
ενός υπολογιστικού σύστήματος: έχουμε
παράλληλες αρχιτεκτονικές, λειτουργικά
συστήματα / συστήματα εκτέλεσης που
υποστηρίζουν τον παραλληλισμό, παράλληλες
γλώσσες / βιβλιοθήκες προγραμματισμού,
παράλληλους αλγορίθμους και μεθοδολογίες
ανάπτυξης λογισμικού και εφαρμογών.
Όμως ενώ τα ακολουθιακά αντίστοιχα
είναι σχετικά καλά ορισμένα, οι παράλληλες
εκδοχές επιτρέπουν αρκετούς βαθμούς
ελευθερίας και συνακόλουθα εναλλακτικές
προσεγγίσεις. Η υιοθέτηση ή μη μιας
προσέγγισης δεν είναι μόνο θέμα ορθότητας
αλλά και τεχνολογικής συγκυρίας.
Μια σημείωση σχετικά με το επίπεδο
προσέγγισης της παράλληλης επεξεργασίας.
Στο φυσικό κόσμο συνήθως διακρίνουμε
τρία επίπεδα προσέγγισης ενός φαινομένου.
Για παράδειγμα, στη Φυσική, έχουμε το
μικρο-επίπεδο της Κβαντομηχανικής, το
μεσο-επίπεδο, της κλασσικής Νευτώνιας
Φυσικής, και το μακρο-επίπεδο της Θεωρίας
της Σχετικότητας. Αντίστοιχα, η ανθρώπινη
συμπεριφορά μπορεί να προσεγγιστεί σε
μικρο-επίπεδο, δηλαδή σε εππίπεδο
βιολογικής και νευροφυσιλογικής
λειτουργίας ενός προσώπου, σε μέσο-επίπεδο,
δηλαδή σε επίπεδο συνειδητής καθημερινής
συμπεριφοράς του ίδιου προσώπου, και
σε μάκρο-επίπεδο, δηλαδή σε επίπεδο
συμπεριφοράς κοινωνικών ομάδων ή και
ολόκληρων πληθυσμών ή ειδών σε ιστορικό
χρόνο. Συνήθως, η συμβατική κατανόηση
της καθημερινότητάς μας και του κόσμου
εστιάζεται στο προσωπικό μας μέσο-επίπεδο.
Σε αυτό το επίπεδο οι σκέψεις και οι
ενέργειές μας, όπως επίσης και η
αλληλεπίδραση με το περιβάλλον είναι
κατα βάση ακολουθιακή: σκεφτόμαστε ένα
πράγμα κάθε φορά, εκτελούμε μια εργασία
κάθε στιγμή κοκ. Η ακολουθιακή προσέγγιση
είναι η πλέον εύλογη. Όμως, αν σκεφούμε
τον εαυτό μας σαν ένα οργανισμό με
δισεκατομμύρια κύτταρα που συντονίζεται
από έναν εγκέφαλο με δισεκατομμύρια
νευρώνες οι οποίοι συνδεόνται μεταξύ
τους με δεκάδες χιλιάδες συνάψεις, και
όλα αυτά λειτουργούν Παράλληληλα και
Κατανεμημένα (Parallel Distributed Processing) για να
επιτύχουν αυτό που ονομάζουμε συνείδηση,
τότε κατανοούμε οτι υπάρχει ένα
καλυμμένος παραλληλισμός στο μικρο-επίπεδο
που είναι απολύτως απαραίτητος για την
επιτυχημένη ακολουθιακή λειτουργία
του μέσου επιπέδου. Αντίστοιχα, αν
σκεφτούμε τον εαυτό μας ως ένα μέρος
ενός κοινωνικού συνόλου τότε η ακολουθιακή
μας δραστηριότητα συντονίζεται με τις
δραστηριότητες άλλων ανθρώπων για τη
παραγωγή ενός ενιαίου αποτελέσματος.
Αυτή η συνεργασία μπορεί να είναι
συνειδητή ή μη, τοπική ή απομακρυσμένη,
χρονικά περιορισμένη ή όχι, κεντρικά
συντονισμένη ή όχι κλπ.
Γιατί Παράλληλη Επεξεργασία;
Οι κύριοι λόγοι
χρήσης της παράλληλης επεξεργασίας
είναι:
Μείωση του χρόνου
εκτέλεσης (και χρημάτων, αν δεχτούμε
οτι "ο χρόνος είναι χρήμα")
Επίλυση μεγαλυτέρων
προβλημάτων (δες π.χ. το Αμερικανικό
Grand Challenge και αντίστοιχες Ευρωπαικές
δράσεις
Επεξεργασία του
συνεχώς αυξανόμενου όγκου κατανεμημένων
δεδομένων που παράγει το Διαδίκτυο ή
άλλες εφαρμογές
Παροχή ταυτόχρονης (concurrent) πρόσβασης
σε ακριβούς πόρους, ίσως και μέσω
εικονικοποίησης (Virtualization)
Μερικοί άλλοι λόγοι:
Χρήση απομακρυσμένων
πόρων μέσω τοπικών δικτύων και
Διαδικτύου.
Μείωση κόστους,
χρήση πολλών "φθηνών" πόρων αντί
λίγων ακριβών (πχ υπερ-υπολογιστών).
Κατανομή δεδομένων σε πολλούς
υπολογιστές ώστε να ξεπεραστούν
περιορισμοί στο μέγεθος της μνήμης.
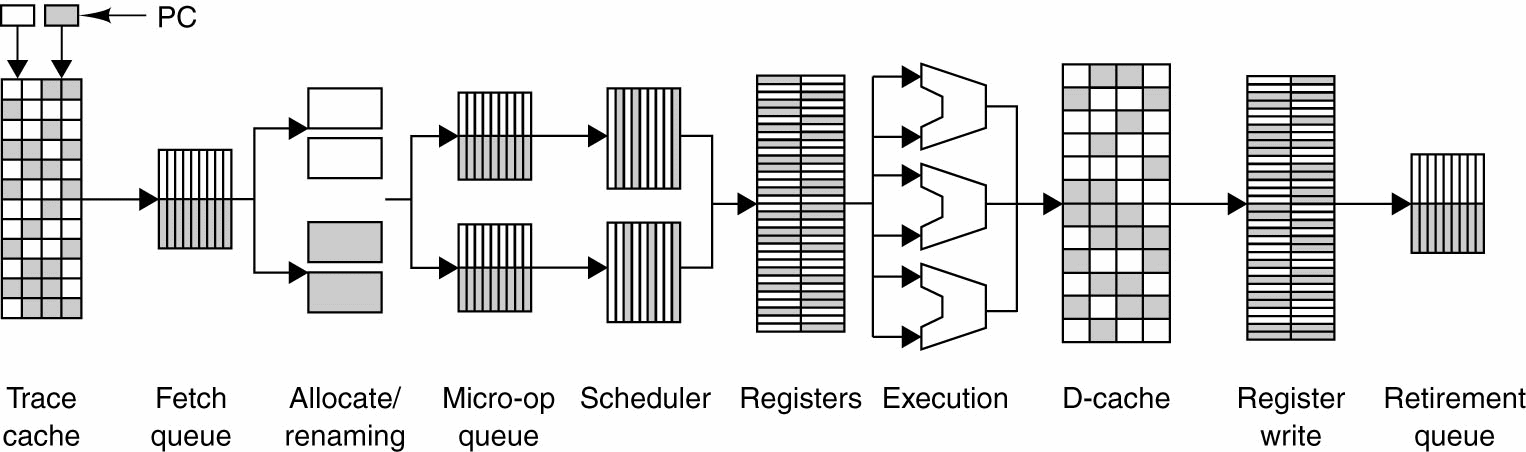
Σχεδιαστικοί περιορισμοί - οι
τεχνολογίες του Παραλληλισμού
Επιπέδου Εντολής (Instruction Level Parallelism)
φαίνεται να έχουν φτάσει στο όριό τους,
με την έννοια οτι οι τεχνολογικές
βελτιώσεις είναι σχετικά μικρές και
παρουσιάζουν μεγάλο κόστος (ILP wall). Το
σχήμα που ακολουθεί συνοψίζει τις
βασικές τεχνικές ILP που συναντώνται σε
ένα σύγχρονο επεξεργαστή: Διοχέτευση
Εντολών και Πράξεων, Πολυνηματική /
Υπερβαθμωτή Εκτέλεση, Εκτέλεση
εντός/εκτός σειράς, Πρόβλεψη διακλαδώσεων,
Προκαταβολική Προσκόμιση και
Ιεραρχία Κρυφής Μνήμης. Παρακάτω
φαίνεται η μικροαρχιτεκτονική μιας
CPU με αρκετά στοιχεία ILP.
|
|
Ποιοί χρησιμοποιούν τη παράλληλη
επεξεργασία σήμερα; Διαπιστώνουμε οτι
πλέον οι 'παραδοσιακοί' τομείς είναι
σχεδόν μειοψηφικοί, ενώ νέοι τομείς
εμφανίζονται. Είναι πλέον φανερό οτι
τόσο σε επίπεδο διακομιστών και data
centers αλλά ακόμη και σε επίπεδο προσωπικών
υπολογιστών η παράλληλη επεξεργασία
κερδίζει συνεχώς έδαφος. Στο www.top500.org
δίνονται πολλές πληροφορίες σχετικά
με τα ισχυρότερα συστήματα στο κόσμο,
την αρχιτεgκτονική τους, τις εφαρμογές
που εκτελούν κλπ. Επίσης υπάρχουν και
πολλά ιστορικά στοιχεία.
Αρχιτεκτονική von Neumann
Για περισσότερα από
40 χρόνια, σχεδόν όλοι οι υπολογιστές
ακολουθούν ένα κοινό μοντέλο, γνωστό
και ως αρχιτεκτονική von Neumann, προς τιμή
του John von Neumann.
Ο υπολογιστής von Neumann βασίζεται στην
έννοια τπυ αποθηκευμένου προγράμματος.
Η CPU εκτελεί ένα αποθηκευμένο πρόγραμμα
που καθορίζει μια ακολουθία αναγνώσεων
και εγγραφών δεδομένων από/προς τη
μνήμη (με ενδιάμεση επεξεργασία τους
στη CPU).
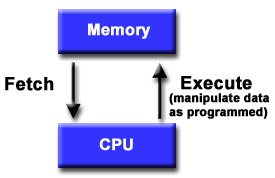
Βασική σχεδίαση:
Τόσο οι εντολές όσο
και τα δεδομένα αποθηκεύονται στη
μνήμη
Οι εντολές του
προγράμματος είναι κωδικοποιημένα
δεδομένα που καθορίζουν λεπτομερώς
τις ενέργειες του υπολογιστή.
Τα δεδομένα είναι
απλά πληροφορία που χρησιμοποιείται
από το πρόγραμμα.
Η CPU εκτελεί συνεχώς το κύκλο
Ανάκλησης-Εκτέλεσης (Fetch-Execute): προσκομίζει
εντολές από τη μνήμη, τις αποκωδικοποιεί,
και τις εκτελεί ακολουθιακά (ή
σειραικά): προσκομίζει δεδομένα από
τη μνήμη, τα επεξεργάζεται με βάση τις
εντολές και αποθηκεύει δεδομένα στη
μνήμη.
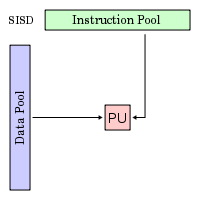
Κλασσική Ταξινόμηση Flynn
Υπάρχουν διάφοροι
τρόποι ταξινόμησης των παράλληλων
υπολογιστών. Μια από τις ευρύτερα
χρησιμοποιούμενες ταξινομήσεις είναι
του Flynn που προτάθηκε το 1966.
Η ταξινόμηση Flynn
διακρίνει τους παράλληλους υπολογιστές
με βάση δύο κριτήρια (διαστάσεις), τη
πολλαπλότητα Εντολών (Instruction)
και Δεδομένων (Data). Κάθε διάσταση
μπορεί να λάβει δύο τιμές: Απλός
(Single) ή Πολλαπλός (Multiple).
Ο παρακάτω πίνακας ορίζει 4 πιθανές
καταστάσεις σύμφωνα με το Flynn.
-
S I S D (Α Ε Α Δ)
Single Instruction, Single
Data
Απλή Εντολή Απλό Δεδομένο
|
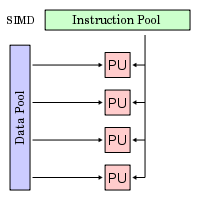
S I M D (Α Ε Π Δ)
Single Instruction, Multiple
Data
Απλή Εντολή Πολλαπλά Δεδομένα
|
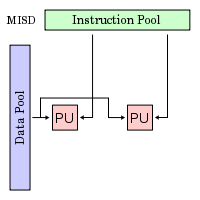
M I S D (Π Ε Α Δ)
Multiple Instruction, Single
Data
Πολλαπλές Εντολές Απλό Δεδομένο
|
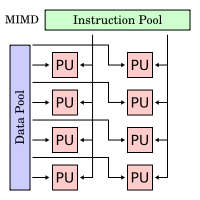
M I M D (Π Ε Π Δ)
Multiple Instruction, Multiple
Data
Πολλαπλές Εντολές Πολλαπλά
Δεδομένα
|
 Απλή Εντολή, Απλό Δεδομένο (ΑΕΑΔ, SISD):
Απλή Εντολή, Απλό Δεδομένο (ΑΕΑΔ, SISD):
Ο τυπικός σειραικός
(μη-παράλληλος) υπολογιστής
Απλή εντολή: μόνο
μια ροή εντολών εκτελείται από τη CPU
σε κάθε χρονική στιγμή (δε λαμβάνεται
υπ' όψη ο Παραλληλισμός Επιπέδου
Εντολής, ILP)
Απλό δεδομένο:
μόνο μια ροή δεδομένων υφίσταται
επεξεργασία σε κάθε χρονική στιγμή
Προσδιοριστική
(Deterministic) εκτέλεση
Το παλαιότερο
και, μέχρι πρόσφατα, το επικρατέστερο
μοντέλο
Παραδείγματα: τα περισσότερα PCs,
σταθμοί εργασίας και κεντρικοί
υπολογιστές
|
|
Απλή Εντολή, Πολλαπλά Δεδομένα (ΑΕΠΔ,
SIMD):
Συνήθως υπάρχει
μια κεντρική μονάδα ελέγχου (CU),
πολλαπλές μονάδες επεξεργασίας (PUs)
σχετικά μικρής ισχύος που συνδέονται
με τη μνήμη και μεταξύ τους με εσωτερικό
δίκτυο διασύνδεσης
Δύο βασικές
εκδοχές: Επεξεργαστές Πινάκων (Array
Processors) και Ανυσματικοί Επεξεργαστές
(Vector Processors)
Απλή εντολή: όλες
οι μονάδες επεξεργασίας (Processing Units,
PUs) εκτελούν την ίδια εντολή σε κάθε
χρονική στιγμή
Πολλαπλά δεδομένα:
κάθε PU επεξεργάζεται διαφορετική ροή
δεδομένων
Σύγχρονη (κεντρικά
συγχρονιζόμενη) και προσδιοριστική
εκτέλεση
Συστήματα ειδικού
σκοπού (και συν-επεξεργαστές) για
προβλήματα με μεγάλο βαθμό κανονικότητας
(πχ επεξεργασία εικόνας, πράξεις
πινάκων).
Πρόκειται για
εξειδικευμένη μορφή παραλληλισμού,
η οποία βασίζεται κυρίως σε επεμβάσεις
στο υλικό και την αρχιτεκτονική.
Επίσης μπορεί να ειδωθεί ως ειδική
περίπτωση της κατηγορίας MIMD.
Βρίσκει σημαντικές
εφαρμογές στην επαναλαμβανόμενη
'ομαλή' επεξεργασία πινακοποιημένων
δεδομένων (συμβολοσειρές, εικόνες,
αλφαριθμητικά, βιολογικά δεδομένα)
καθώς και ροών δεδομένων (ήχος, πακέτα
δικτύου, σήμα, video).
Οι Μονάδες Επξεργασίας Γραφικών
(Graphic Processing Units, GPUs) είναι το πιο
πετυχημένο παράδειγμα SIMD αρχιτεκτονικής
σήμερα. Παρακάτω φαίνεται ένα τέτοιο
παράδειγμα.
|
|
Πολλαπλές Εντολές, Απλό Δεδομένο
(ΠΕΑΔ, MISD):
Μια ροή δεδομένων
τροφοδοτεί πολλαπλές PUs
Κάθε PU επεξεργάζεται
τα δεδομένα ανεξάρτητα μέσω ανεξάτρητων
ροών εντολών
Ελάχιστα πρακτικά
παραδείγματα, όπως ο πειραματικός
υπολογιστήC.mmp του πανεπιστημίου
Carnegie-Mellon C.mmp (1971)
Μερικές πιθανές
χρήσεις:
|
|
Πολλαπλές Εντολές, Πολλαπλά Δεδομένα
(ΠΕΠΔ, MIMD):
Ο πλέον διαδεδομένος
τύπος παράλληλου υπολογιστή. Σταδιακά,
με την έλευση των πολυ-πύρηνων
συστημάτων, τείνει να καταστεί ο πλέον
διαδεδομένος τύπος υπολογιστή. Συνήθως
υπάρχουν πολλαπλούς επεξεργαστές
(CPUs) που συνδέονται μεταξύ τους
είτε με δίαυλο και μοιραζόμενη μνήμη
είτε με εσωτερικό δίκτυο και κατανεμημένη
μνήμη είτε πρόκειται για κοινούς
υπολογιστές συνδεδεμένους μέσω
δικτύου.
Δύο βασικές
εκδοχές: Μοιραζόμενης Μνήμης ή
Πολυ-επεξεργαστές (Shared Memory,
Multi-processors) και Κατανεμημένης Μνήμης
ή Πολυ-υπολογιστές (Distributed Memory,
Multi-computers)
Πολλαπλές εντολές:
κάθε CPU μπορεί να εκτελεί διαφορετική
ροή εντολών ή διαφορετική εντολή από
την ίδια ροή εντολών
Πολλαπλά δεδομένα:
κάθε CPU μπορεί να επεξεργάζεται
διαφορετική ροή δεδομένων ή διαφορετικό
δεδομένο από την ίδια ροή
Η εκτέλεση συνήθως
είναι ασύγχρονη (ένα ρολόι ανά
επεξεργαστή) και ίσως μη-προσδιοριστική
(αν δεν προβλεφθεί επαρκής συντονισμός)
Η συντριπτική
πλειονότητα των παράλληλων συστημάτων
εμπίπτει σε αυτή τη κατηγορία, με την
οποία ασχολούμαστε στο υπόλοιπο
κείμενο. Διαγράμματα και παραδείγματα
θα δούμε στις επόμενες ενότητες
Παραδείγματα:
Αρχιτεκτονικές
Μοιραζόμενης Μνήμης (Shared Memory):
Πολυ-πύρηνα συστήματα (Multi-core),
Συμμετρικοί Πολυ-Επεξεργαστές
(Symmetric Multi-Processors)
Αρχιτεκτονικές
Κατανεμημένης Μνήμης (Distributed Memory):
Networks of Workstations (NOWs), Συστοιχίες
(Clusters), Κατανεμημένοι Υπολογιστές
(τύπου BOINC).
Υβριδικά Συστήματα: Αποτελούν
τη μεγάλη πλειοψηφία των σύγχρονων
υπερυπολογιστών και συνδυάζουν τις
παραπάνω κατηγορίες. Θα αναλυθούν
παρακάτω.
|
|
Γενική Ορολογία
Παρακάτω εμφανίζονται μερικοί συχνά
εμφανιζόμενοι όροι της παράλληλης
επεξεργασίας. Μερικοί έχουν ήδη
εμφανιστεί, οι περισσότεροι αναλύονται
αργότερα στο κείμενο:
- Κόμβος (Node)
-
Ένας αυτόνομος υπολογιστής (που θα
μπορούσε να λειτουργήσει αυτόνομα, αν
δεν ανήκε σε ένα παράλληλο σύστημα).
Συνήθως περιέχει πολλαπλούς πυρήνες
ή συνεπεξεργαστές (GPUs).
-
Κεντρική Μονάδα Επεξεργασίας (Central
Processing Unit, CPU) / Πυρήνας (Core)
-
Μέχρι πριν μερικά χρόνια η CPU είχε τη
μορφή που ορίζεται στο Μοντέλο Von Neuman
(SISD), με τις εσωτερικές επεκτάσεις των
τεχνολογιών Παραλληλισμού Επιπέδου
Εντολής (Instruction Level Parallelism), που
παρουσιάστηκαν σύντομα παραπάνω. Όμως
πλέον η CPU έχει ταυτιστεί με την έννοια
του Πυρήνα (Core), ενώ ένα ολοκληρωμένο
κύκλωμα CPU πλέον περιλαμβλανει 4, 6 ή και
παραπάνω Πυρήνες (άρα πλήρεις CPUs). Αυτές
διασυνδέονται με εσωτερικό δίαυλο και
μοιράζονται τα υψηλότερα επίπεδα της
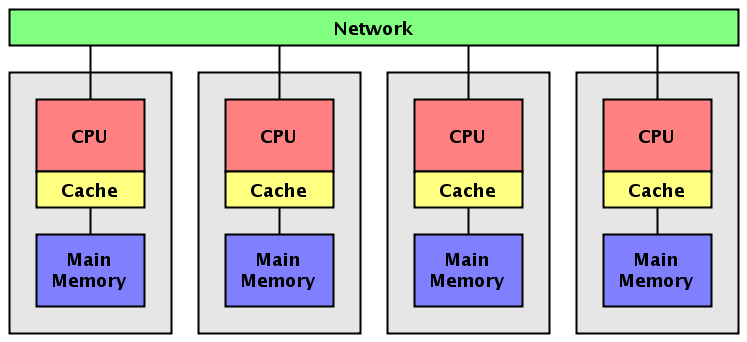
Ιεραχίας Κρυφής Μνήμης. Κάθε Κόμβος
(Node) ενός Παράλληλου συστήματος συνήθως
περιέχει 1 ή περισσότερα ολοκληρωμένα
κυκλώματα CPUs, άρα αρκετούς Πυρήνες. Η
εικόνα που ακολουθεί δείχνει μια τυπική
συστοιχία με πολυπύρηνους κόμβους.
-
-

-
-
-
Μονάδα Επεξεργασίας (Processing Unit, PU)
-
Ένας συνδυασμός ALU και Τοπικής Μνήμης.
Συνήθως χρησιμοποιείται σε συστήματα
SIMD όπου μια μεγάλη ομάδα PEs ελέγχονται
από μια Μονάδα Ελέγχουυ και εκτελούν
τους ίδιους υπολογισμούς σε διαφορετικά
δεδομένα. Τυπικό παράδειγμα οι
επεξεργαστές των GPUs.
-
Μονάδα Επεξεργασίας Γραφικών (Graphics
Processing Unit, GPU)
-
Συν-επεξεργαστές τύπου SIMD που διαθέτουν
αρκετές εκατοντάδες PUs οργανωμένα σε
ομάδες (blocks) με κοινή μνήμη. Τα PUs μπορούν
να προσπελάσουν τα δεδομένα στη μνήμη
τους σε μορφή ανύσματος ή πολυδιάστατου
πίνακα. Οι GPUs επιτυγχάνουν εντυπωσιακές
αποδόσεις στην ομαλή (χωρίς σημαντικές
διακλαδώσεις ή πρόσβαση σε ανώτερα
επίπεδα της ιεραρχίας μνήμης) επεξεργασία
μεγάλου όγκου πινακοποιημενων δεδομένων.
Χρησιμοποιούνται ως συνεπεξεργαστές
σε σύγχρονα υβριδικά παράλληλα συστήματα.
Παρακάτω φαίνεται το διάγραμμα μιας
τυπικής GPU (αριστερά) και ενός block PUs
(δεξιά).

|
|
-
Δίκτυο Διασύνδεσης (Interconnection Network)
-
Tα εξαρτήματα του παράλληλου υπολογιστή
που είναι υπεύθυνα για την υλοποίηση
της επικοινωνίας μεταξύ επεξεργαστών
ή επεξεργαστών και μνήμης ή ολόκληρων
υπολογιστών. Το δίκτυο διασύνδεσης
συνήθως μπορεί να είναι ένας απλός
δίαυλος (bus) ή μια τυπική υποδομή τοπικού
δικτύου. Όμως σε μεγαλύτερα παράλληλα
συστήματα το δίκτυο διασύνδεσης είναι
αρκετά περίπλοκες κατασκευές όπως
crossbar switches, διακοπτικά συστήματα πολλαπλών
σταδίων, πλέγματα, δακτύλιοι, δένδρα,
υπερκύβοι διαφόρων διαστάσεων κλπ.
-
Εργασία (Task)
-
Μια λογικά διακριτή ενότητα υπολοιστικής
εργασίας η που εκτελείται από ένα
επεξεργαστή. Λογικά εμφανίζεται ως
πρόγραμμα, υπο-πρόγραμμα (sub-routine),
διαδικασία (procedure), συνάρτηση (function) ή
μέθοδος (method). Συνήθως υλοποιείται
σαν διεργασία (process) ή νήμα (thread)
-
Παράλληλη Εργασία (Parallel Task)
-
Μια εργασία γραμμένη έτσι ώστε να μπορεί
να εκτελεστεί ορθά από πολλαπλούς
επεξεργαστές
-
Σειραική - Ακολουθιακή Εκτέλεση
(Serial - Sequential Execution)
-
Συμβατική εκτέλεση ενός προγράμματος,
μια εντολή κάθε φορά, όπως συμβαίνει
σε συστήματα ενός επεξεργαστή (δε
λαμβάνεται υπ' όψη ο Παραλληλισμός
Επιπέδου Εντολής, ILP). Όμως, σχεδόν όλα
τα παράλληλα προγράμματα έχουν κάποιο
τμήμα που απαιτεί ακολουθιακή εκτέλεση
-
Παράλληλη Εκτέλεση (Parallel Execution)
-
Εκτέλεση ενός προγράμματος με χρήση
πολλαπλών (παράλληλων) εργασιών, έτσι
ώστεοι εργασίες μπορούν την ίδια χρονική
στιγμή να εκτελούν ίδιο ή διαφορετικό
τμήμα του προγράμματος
-
Μοιραζόμενη Μνήμη (Shared Memory)
-
Από πλευράς υλικού, πρόκειται για
παράλληλη αρχιτεκτονική, υποκατηγορία
MIMD, όπου όλοι οι επεξεργαστές έχουν
άμεση (συνήθως μέσω διαύλου) και ισότιμη
πρόσβαση σε κοινή φυσική μνήμη. Από
πλευράς προγραμματιστικού μοντέλου,
ο όρος περιγράφει ένα σύστημα όπου όλες
οι παράλληλες εργασίες έχουν ενιαίο
χώρο φυσικών διευθύνσεων ("βλέπουν"
λογικά την ίδια μνήμη) ανεξάρτητα από
τη φυσική θέση της μνήμης (συνήθως η
προσπέλαση στις θέσεις μνήμης δεν είναι
ακριβώς ισότιμη)
-
Κατανεμημένη Μνήμη (Distributed Memory)
-
Από πλευράς υλικού, πρόκειται για
παράλληλη αρχιτεκτονική, υποκατηγορία
ΜIMD, όπου ο κάθε επεξεργαστής έχει άμεση
πρόσβαση σε ιδιωτική τοπική μνήμη, ενώ
η πρόσβαση στη μνήμη άλλων επεξεργαστών
επιτυγχλανεται συνήθως μέσω δικτύου
(ειδικού ή γενικού). Από πλευράς
προγραμματιστικού μοντέλου, ο όρος
περιγράφει ένα σύστημα όπου οι παράλληλες
διεργασίες έχουν διαφορετικό χώρο
φυσικών διευθύνσεων ("βλέπουν"
λογικά ξεχωριστή μνήμη) και πρέπει
να χρησιμοποιήσουν ειδικές προγραμματιστικές
δομές για να προσπελάσουν δεδομένα που
"βλέπουν" άλλες εργασίες
-
Επικοινωνία (Communication)
-
Συνήθως οι παράλληλες διεργασίες πρέπει
να ανταλλάξουν δεδομένα. Υπάρχουν δύο
βασικοί τρόποι επικοινωνίας δεδομένων:
είτε έμμεσα, μέσω κοινών θέσεων μνήμης
(μοιραζόμενη μνήμη) ή άμεσα, μέσω
μεταβίβασης ων δεδομένων μέσω δικτύου.
Ο όρος επικοινωνία εργασιών ή δεδομένων
χρησιμοποιείται και στις δύο περιπτώσεις.
Συνήθως η επικοινωνία επιφέρει σχετικές
καθυστερήσεις καθώς κατά την ανταλλαγή
δεδομένων πιθανώς κάποια παράλληλη
εργασία να πρέπει να αναμένει δεδομένα
για να συνεχίσει την εκτέλεσή της
-
Συγχρονισμός (Synchronization)
-
Συντονισμός της εκτέλεσης των (ασύγχρονων)
παραλλήλων εργασιών σε πραγματικό
χρόνο, που συνήθως επιτυγχάνεται μέσω
επικοινωνίας (αρχιτεκτονικές MIMD).
Συνήθως η κάθε παράλληλη εργασία
περιέχει στο κώδικά της δομές συγχρονισμού,
οι οποίες απαιτούν την επικοινωνία με
άλλες εργασίες πριν η εργασία συνεχίσει
την εκτέλεσή της. Ο συχγρονισμός υπονοεί
οτι τουλάχιστο μια εργασία θα αναμένει,
άρα ο αντίστοιχος επεξεργαστής θα είναι
άεργος. Στις αρχιτεκτονικές SIMD η εκτέλεση
των εντολών στις μονάδες επεξεργασίας
είναι εξ' ορισμού σύγχρονη
-
Κοκκιότητα (Granularity)
-
Στη παράλληλη επεξεργασία, η κοκκιότητα
είναι ένα μέτρο του λόγου υπολογισμού
προς επικοινωνία (computation to
communication rate).
-
Αδρομερής (Coarse): ο υπολογιστικός
φόρτος μιας παράλληλης εργασίας είναι
πολύ μεγαλύτερος από την επικοινωνία
της.
-
Λεπτομερής (Fine): ο υπολογιστικός
φόρτος μια παράλλλης εργασίας είναι
συγκρίσιμος με την επικοινωνία της.
- Από πλευράς υλικού ο υπολογιστικός
φόρτος και η επικοινωνία εξαρτώνται
από την ισχύ του επεξεργαστή και τη
ταχύτητα του δικτύου ή διαύλου. Επομένως,
με εξαίρεση εξειδικευμένα συστήματα,
τυπικά η επικοινωνία είναι πολύ πιο
δαπανηρή από τον υπολογισμό, ιδιαίτερα
στα συσήματα κατανεμημένης μνήμης
-
Σύνδεση (Coupling)
-
Στη παράλληλη επεξεργασία, η σύνδεση
είναι ένα μέτρο της εγγύτητας των
υπολογιστικών μονάδων.
-
Στενά Συνεδεδμένο (Tightly-Coupled): οι
υπολογιστικές μονάδες επικοινωνούν
σε σχετικά υψηλές ταχύτητες και
μοιράζονται πόρους (πχ κοινή μνήμη).
-
Χαλαρά Συνδεδεμένο (Loosely-Coupled): οι
υπολογιστικές μονάδες επικοινωνούν
σε σχετικά χαμηλές ταχύτητες και δεν
μοιράζονται πόρους.
- Μαζικά Παράλληλος Επεξεργαστής
(Massively Parallel Processor)
-
Αναφέρεται σε ειδικά παράλληλα συστήματα
με πολύ μεγάλο αριθμό επεξεργαστών -
για τη συγκεκριμένη τεχνολογία
(συντομογραφία ΜPP). Συνήθως εννοούμε
χιλιάδες επεξεργαστές. Τα δικτυα
διασύνδεσης των MPPs προφανώς δεν μπορεί
να είναι ούτε συμβατικοί δίαυλοι ούτε
και τοπικά δίκτυα διαχωρισμός από
συστοιχίες, clusters). Συνήθως χρησιμοποιούνται
ιεραρχικά συνδεδεμένα συστήματα
μεταγωγής ή ειδικά διασυνδετικά δίκτυα.
-
-
Πράξεις Κινητής Υποδιαστολής Ανά
δευτερόλεπτο (Floating Poinf Operations Per Second,
FLOPS)
-
Συνηθισμένο μέτρο σύγκρισης της απόδοσης
παράλληλων υπολογιστών. Το μέτρο
προκύπτει ως μέσος όρος εκτέλεσης μιας
συγκεκριμένης ομάδας μετρο-προγραμμάτων
(benchmarks) και αποτελεί το βασικό κριτήριο
κατάταξης στο Top500. Ακολουθεί σχετικός
πίνακας.
-
-

-
-
Επιτάχυνση (Speedup)
-
Η επιτάχυνση ενός παραλληλοποιημένου
προγράμματος ορίζεται ως ο λόγος:
-
χρόνος ακολουθιακής εκτέλεσης
χρόνος παράλληλης εκτέλεσης
|
- Εννοείται οτι η
επιτάχυνση ορίζεται για εκτέλεση μιας
εφαρμογής συγκεκριμένου μεγέθους
προβλήματος με συγκεκριμένο αριθμό
επεξεργαστών και ίδιο αλγόριθμο και
δεδομένα όπως η ακολουθιακή. Είναι ένας
από τους απλούστερους και ευρύτερα
χρησιμοποιούμενους δείκτες απόδοσης
στη παράλλη επεξεργασία. Γραμμική
(Linear) ονομάζεται η επιτάχυνση όταν
αυξάνεται ανάλογα με τον αριθμό των
χρησιμοποιούμενων επεξεργαστών, και
αποτελεί μέτρο ιδανικής παραλληλοποίησης.
-
Επιβάρυνση (Overhead)
-
Ο χρόνος παράλληλης εκτέλεσης που
δαπανάται για το συντονισμό των
παραλλήλων εργασιών σε αντίθεση με τον
χρόνο ωφέλιμου υπολογισμού (δηλαδή
αυτόν που εκτελεί το πρόγραμμα και στην
ακολουθιακή του μορφή). Η επιβάρυνση
εξαρτάται από παράγοντες όπως:
-
Δημιουργία και διανομή εργασιών
-
Συγχρονισμός
-
Επικοινωνία
-
Τερματισμός εργασιών
-
Κλήσεις συστήματος, χρήση βιβλιοθηκών,
οδηγίες μεταγλωττιστών κλπ
-
Κόστος και Ωφελιμότητα (Cost and Utilization)
-
Το κόστος ορίζεται ως το γινόμενο:
-
χρόνος (παράλληλης ή ακολουθιακής)
εκτέλεσης * αριθμός επεξεργαστών (1
για ακολουθιακή εκτέλεση)
-
Η ωφελιμότητα ορίζεται ως [ακολουθιακό
κόστος / παράλληλο κόστος]% ή αλλιώς
-
-
[επιτάχυνση / αριθμός επεξεργαστών]%
-
-
και δίνει ένα ποσοτικό μέτρο της
συνολικής επιβάρυνσης της παράλληλης
εκτέλεσης. Ωφελιμότητα 100% σημαίνει
μηδενική επιβάρυνση, δηλαδή ιδανική
παραλληλοποίηση.
-
-
Μεγέθυνση (Sizeup)
-
Αναφέρεται στη μεταβολή της επιτάχυνσης
μιας παράλληλης εφαρμογής όταν αυξάνεται
το μέγεθος του προβλήματος αλλά
διατηρείται σταθερός ο αριθμός των
επεξεργαστών (ή το μέγεθος του προβλήματος
διατηρείται σταθερό και μειώνεται ο
αριθμός των επεξεργαστών). Σταδιακά
η ωφελιμότητα προσγεγγίζει ένα μέγιστο,
δηλαδή οι δυνατότητες παραλληλισμού
της συγκεκριμένης λύσης τείνουν να
εξαντληθούν. Στη συνέχεια η παραπέρα
αύξηση του μεγέθους του προβλήματος
(ή μείωση του αριθμού των επεξεργαστών)
οδηγεί σε αύξηση του χρόνου εκτέλσης.
-
Κλιμάκωση (Scaleup)
-
Αναφέρεται στη δυνατότητα μιας παράλληλης
εφαρμογής να διατηρήσει σταθερή
επιτάχυνση με την αύξηση του μεγέθους
του επιλυόμενου προβλήματος και
αντίστοιχη αύξηση του αριθμού των
επεξεργαστών.
-
-
Οι παράγοντες που συνεισφέρουν σε
ικανοποιητική μεγέθυνση και κλιμάκωση
σχετίζονται με το υλικό και το λογισμικό:
-
Ταχύτητα επεξεργαστών και εύρος ζώνης
μνήμης
-
Ταχύτητα διαύλου ή δικτύου επικοινωνίας
-
Δυνατότητες αποθηκευτικού χώρου και
ταχύτητα Εισόδου/Εξόδου
-
Αλγόριθμος που εφαρμόζεται
-
Επιβάρυνση (δηλαδή μέτρα όπως επιτάχυνση
και ωφελιμότητα)
-
Άλλα χαρακτηριστικά της εφαρμογής, του
μεταγλωττιστή, του λειτουργικού
συστήματος κλπ.
Αρχιτεκτονικές Παράλληλων Υπολογιστών
|
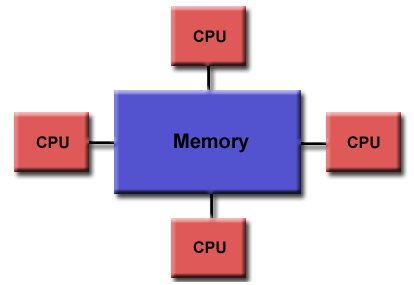
Υπολογιστές Μοιραζόμενης Μνήμης ή
Πολυ-Επεξεργαστές
Γενικά Χαρακτηριστικά:
Shared Memory
Πλεονεκτήματα:
Ο καθολικός χώρος
φυσικών διευθύνσεων επιτρέπει ένα
μοντέλο προγραμματισμού φιλικό προς
το χρήστη, αφού είναι παρόμοιο με αυτό
του ακολουθιακού προγραμματισμού
Η επικοινωνία και ο συγχρονισμός
είναι εύκολα και γρήγορα λόγω της
μοιραζόμενης μνήμης και μέ χρήση
προγραμματιστικών τεχνικών του
Συντρέχοντος (Concurrent) προγραμματισμού.
Μειονεκτήματα:
Κύριο μειονέκτημα
είναι η έλλειψη κλιμάκωσης στον αριθμό
επεξεργαστών. Η πρόσθεση CPUs αυξάνει
ταχύτατα τη κυκλοφορία στο δίαυλο της
μνήμης, καθώς επίσης και τη κίνηση που
σχετίζεται με τη συνοχή κρυφής μνήμης.
Η προσπάθεια να
παρακαμφθεί το πρόβλημα της κλιμάκωσης
με τη χρήση ειδικού υλικού, πχ μνήμη
μεγάλου εύρους ζώνης ή ειδικοί δίαυλοι
και διασυνδετικά δίκτυα, αυξάνει
σημαντικά το κόστος και δυσκολεύει την
συντήρηση/αναβάθμιση του συστήματος.
Ο προγραμματιστής πρέπει να
χρησιμοποιήσει με επιτυχία τεχνικές
συντρέχοντος (Concurrent) προγραμματισμού.
Ομοιόμορφη και Ανομοιόμορφη Προσπέλαση
Μνήμης (Uniform and Non-Uniform Memory Access, UMA):
Οι συνηθέστεροι
πολυ-επεξεργαστές μέχρι πρόσφατα ήταν
οι Συμμετρικοί Πολυ-Επεξεργαστές
(Symmetric Multi-Pprocessors, SMPs). Σταδιακά
αντικαθίστανται από (ή αποτελούνται
από) Πολυ-Πύρηνους (Multi-Core) Επεξεργαστές
οι οποίοι από πλευράς προγραμματισμού
είναι πολυ-επεξεργαστές σε σμίκρυνση.
Και στις δύο παραπάνω κατηγορίες
οι επεξεργαστές του συστήματος είναι
πανομοιότυποι (εξ' ου και "συμμετρικοί").
Επίσης όλοι οι επεξεργαστές έχουν ίσους
χρόνους προσπέλασης στη μοιραζόμενη
μνήμη (Ομοιόρφη Προσπέλαση Μνήμης,
Uniform Memory Access, UMA). Υποστηρίζεται
Cache Coherency (CC) γι' αυτό ονομάζονται και
CC-UMA.
Μια μέθοδος ξεπεράσματος
του προβλήματος της κλιμάκωσης είναι
η φυσική σύνδεση δύο ή περισσοτέρων
SMPs ή Multi-Cores με ειδικό διασυνδετικό
δίκτυο.
Το ένα SMP έχει δυνατότητα προσπέλασης
στη μνήμη του άλλου αλλά ο χρόνος
προσπέλασης της απομακρυσμένης μνήμης
δεν είναι ίσος με αυτό της τοπικής του
μνήμης (Ανομοιόρφη Προσπέλαση
Μνήμης, Non-Uniform Memory Access, NUMA). Μπορεί
να υποστηρίζεται cache cohernecy ή οχι.
Shared Memory NUMA
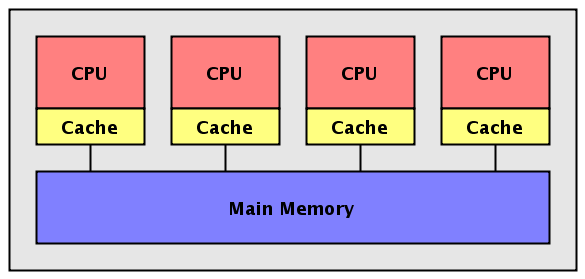
Συνοχή Κρυφής Μνήμης (Cache Cohernece)
Στα σύγχρονα
πολυπύρηνα συστήματα, σε κάθε CPU (core)
εννοείται η ύπαρξη μνήμης Cache, με στόχο
την απρόσκοπτη τροφοδοσία της CPU με
δεδομένα και τη μείωση της κυκλοφορίας
στο δαυλο μνήμης. O όρος συνοχή κρυφής
μνήμης σημαίνει οτι όταν ένας
επεξεργαστής ενημερώνει μια θέση της
κρυφής του μνήμης, τότε όλοι οι άλλοι
επεξεργαστές - και η κύρια μνήμη -
ενημεώνονται έγκαιρα γι' αυτή τη
τροποποίηση. Για τα συστήματα Shared
memory UMA η συνοχή κρυφής μνήμης είναι
δεδομένη και επιτυγχάνεται σε επίπεδο
υλικού, διαφανώς για το προγραμματιστή.
Υπάρχουν δύο βασικο αλγόριθμοι. O
write-through αλγόριθμος Snooping Cache, ο οποίος
είναι απλός αλλά δαπανηρός, ειδικά όσο
ο αριθμός των CPUs αυξάνει. O write-back αλγόριθμος
MESI (Modified, Exclusive, Shared, Invalid) είναι ο πιο
δημοφιλής αλγόριθμος. Για τα συστήματα
Shared Memory NUMA η συνοχή κρυφής μνήμης
δεν είναι δεδομένη, αλλά σταδιακά γίνεται
απαραίτητη. Το πιο συνηθισμένο πρωτόκολλο
στηρίζεται σε καταλόγους (Directory Based).
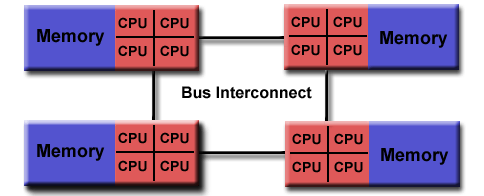
Αρχιτεκτονικές Παράλληλων Υπολογιστών
|
Υπολογιστές Κατανεμημένης Μνήμης ή
Πολυ-Υπολογιστές
Γενικά Χαρακτηριστικά:
Παρόμοια, οι αρχιτεκτονικές
κατανεμημένης μνήμης διαφέρουν μεταξύ
τους, αλλά παρουσιάζουν ένα κοινό
χαρακτηριστικό: κάθε επεξεργαστής έχει
τοπική (ιδιωτική) μνήμη ενώ η επικοινωνία
με απομακρυσμένη μνήμη (τοπική μνήμη
των άλλων επεξεργαστών) επιτυγχάνεται
μέσω δικτύου και συνήθως με τη ρητή
συμμετοχή του απομακρυσμένου επεξεργαστή.
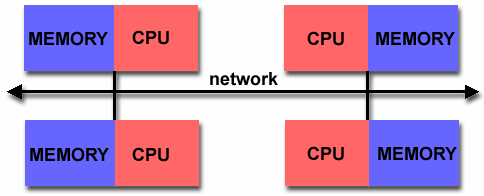
|
|
Ο κάθε επεξεργαστής
έχει τον ιδιωτικό του χώρο διευθύνσεων,
έτσι δεν υπάρχει η έννοια του καθολικού
χώρου διευθύνσεων, κοινού για όλους
τους επεξεργαστές.
Αφού ο κάθε επεξεργαστής
έχει τη δική του τοπική μνήμη, πιθανές
τροποποιήσεις σε θέσεις μνήμης ενός
επεξεργαστή δεν επηρρεάζουν τη
μνήμη άλλων επεξεργαστών. Η κρυφή μνήμη
λειτουργεί ακριβώς όπως και στα συμβατικά
συστήματα και δεν τίθεται ζήτημα συνοχής
της κρυφής μνήμης.
Όταν ένας επεξεργαστής
πρέπει να προσπελαει δεδομένα
απομακρυσμένης μνήμης, συνήθως ο
προγραμματιστής πρέπει ρητά να ορίσει
πότε και ποιά δεδομένα θα προσπελαστούν.
Παρόμοια ο συγχρονισμός μεταξύ παράλληλων
εργασιών σε διαφορετικούς επεξεργαστές
γίνεται ρητά από το πρόγραμμα.
Οι τεχνολογίες δικτύου που
χρησιμοποιούνται κυμαίνονται από απλό
Ethernet μέχρι ειδικά υπερταχέα δίκτυα.
Επίσης η επικοινωνία μπορεί να είναι
καθολική ή σημειακή (δηλαδή να υφίσταται
κάποια τοπολογία, όπως γραμμή, δακτύλιος,
πλέγμα, τόρος, δένδρο, υπερκύβος κλπ):
μπορεί να έχουμε δηλαδή ομοιόμοφη και
ανομοιόμορφη επικοινωνία.
Πλεονεκτήματα:
Ο αριθμός των
επεξεργαστών και το μέγεθος της μνήμης
κλιμακώνονται σχετικά εύκολα.
Ο κάθε επεξεργαστής
έχει τοπική μνήμη στην οποία έχει
απρόσκοπτη και ταχεία πρόσβαση, χωρίς
επιβαρύνσεις διαμοιρασμού και συνοχής
κρυφής μνήμης. Σε αυτό το επίπεδο ο
προγραμματισμός μοιάζει με τον
συμβατικό.
Μπορούμε να χρησιμοποιήσουμε
συμβατικούς υπολογιστές και τεχνολογίες
δικτύου, περιορίζοντας δραματικά το
κόστος κατασκευής, συντήρησης και
αναβάθμισης του παράλληλου συστήματος.
Μειονεκτήματα:
Το μοντέλο
προγραμματισμού για την επικοινωνία
δεδομένων και τον συγχρονισμό είναι
αρκετά σύνθετο, απαιτείται ρητός
προγραμματισμός αρκετών λεπτομερειών.
Είναι δύσκολη η
απεικόνιση σύνθετων δομών δεδομένων
σε κατανεμημένη μνήμη, ιδίως όταν οι
εφαρμογές απαιτούν καθολική επικοινωνία
μεταξύ δεδομένων σε διάφορα στάδια του
προγράμματος. Μπορεί να απαιτηθούν
σημαντικές μετακινήσεις δεδομένων.
Οι χρόνοι προσπέλασης
στη μνήμη δεν είναι ομοιόμορφοι.
Ο λόγος υπολογισμού προς επικοινωνία
επιβάλλει συνήθως αδρομερή παραλληλισμό,
επομένως η κλιμάκωση μπορεί να επιτευχθεί
μόνο με μεγάλα μεγέθη δεδομένω και για
εφαρμογές που απαιτούν σχετικά
περιορισμένη επικοινωνία.
Κατανεμημένη Μοιραζόμενη Μνήμη
(Distributed Shared Memory)
Από αρχιτεκτονική άποψη, αν το κόστος
επικοινωνίας δεν είναι πολύ μεγαλύτερο
από αυτό της πρόσβασης στη μοιραζόμενη
μνήμη, ένα σύστημα Κατανεμημένης
Μνήμης μπορεί να αντιμετωπιστεί ως
σύστημα Μοιραζόμενης Μνήμης NUMA. Γίνονται
προσπάθειες για την ανάπτυξη τεχνικών
σε επίπεδο υλικού αλλά και λογισμικού
για την ανάπτυξης ενός ενοποιημένου
συστήματος (πχ Κατανεμημένης
Μοιραζόμενης Μνήμης, Distributed Shared Memory,
DSM) αλλά ακόμη η επιβάρυνση του
υλικού, του λειτουργικού συστήματος ή
του συστήματος εκτέλεσης είναι σημαντική.
Αρχιτεκτονικές Παράλληλων Υπολογιστών
|
Υβριδικοί Παράλληλοι
Υπολογιστές
Οι μεγαλύτεροι και ταχύτεροι
σύγχρονοι υπολογιστές συνδυάζουν τις
αρχιτεκτονικές μοιραζόμενης και
κατανεμημένης μνήμης. Τυπικά, στην
απλoύστερη εκδοχή έχουμε Πολυ-Πύρηνους
επεξεργαστές συνδεδεμένους μέσω ενός
γρήγρου τοπικού δικτύου. Εναλλακτικά,
ο κάθε κόμβος μπορεί να διαθέτει και
GPUs ως συνεπεξεργαστές, επιτρέποντας
μια σύνθετη αρχιτεκτονική που περιλαμβάνει
Distributed Memory MIMD, Shared Memory MIMD και SIMD συστήματα
στον ίδιο παράλληλο υπολογιστή.
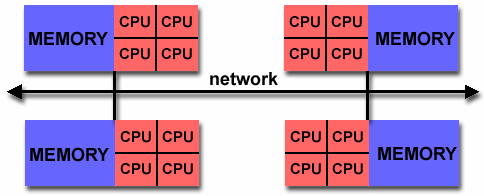
|

|

O κάθε κόμβος είναι
ένα UMA σύστημα μοιραζόμενης μνήμης. Οι
επεξεργαστές έχουν πρόσβαση στη
μοιραζόμενη τοπική μνήμη του κόμβου,
με συνοχή κρυφής μνήμης. Επι πλέον
μπορεί να διαθέτουν GPU συνεπεξεργαστ'ές.
Οι κόμβοι είναι
συνδεδεμένοι μεταξύ τους με δίκτυο,
έτσι ώστε ο κάθε κόμβος έχει πρόσβαση
στη μνήμη των υπολοίπων κόμβων με τη
λογική της κατανεμημημένης μνήμης.
Οι τρέχουσες τάσεις της τεχνολογίας
δείχνουν οτι το μέλλον βρίσκεται στις
υβριδικές παράλληλες αρχιτεκτονικές.
Τα σύγχρονα μεγάλα Clusters και ΜPP's ανήκουν
σε αυτή τη κατηγορία. Η βασική διαφοροποίηση
μεταξύ των δύο κατηγοριών είναι οτι
στα μεν Clusters χρησιμοποιύνται ιεραρχικά
συνδεδεμένες διακοπτικές διατάξεις
τοπικoύ δικτύου (πχ Gigabit Ethernet, Infiniband
switches) ενώ στα MPP's χρησιμοποιoύνται ειδικά
διασυνδετικά δίκτυα τα οποία επιτρέπουν
ταχύτατη (σημειακή ή σε blocks) σύνδεση
μεταξύ ενός υποσυνόλου επεξεργαστών
και πιο αργή σύνδεση (μέσω δικτύου) με
τα πλέον απομακρυσμένους επεξεργαστές.
Παρακάτω εμφανίζονται δύο τέτοια
συστήματα: ένα διάγραμμα Cluster της Google
και ο ΜPP Blue Gene της IBM.
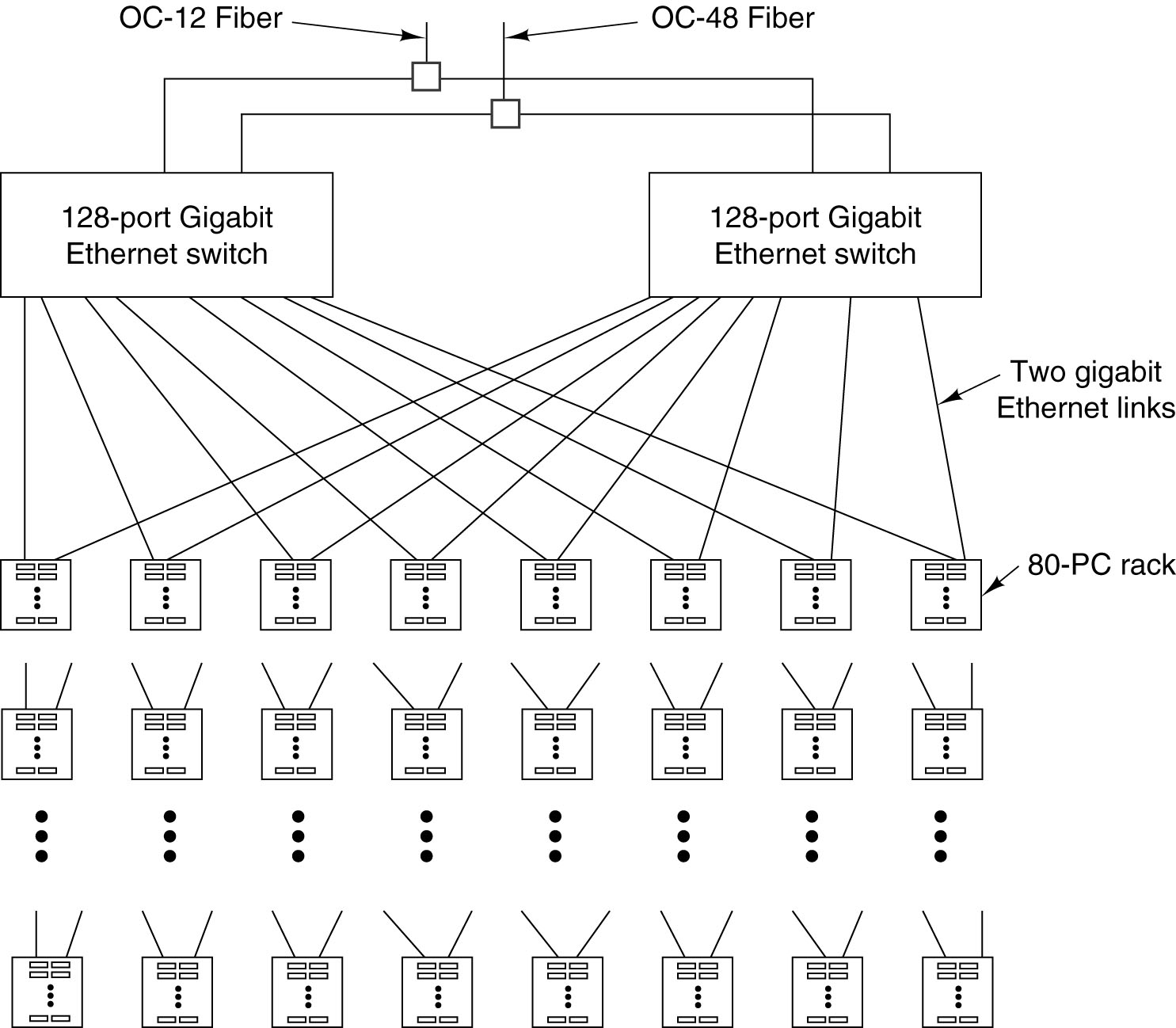
|
|
Πλεονεκτήματα και Μειονεκτήματα:
Από τη πλευρά του υλικού οι υβριδικές
αρχιτεκτονικές είναι η προφανής λύση
για την κλιμακούμενη εκμετάλλευση του
άφθoνου υλικού που έχουμε στη διάθεσή
μας. Από τη πλευρά του προγραμματισμού
το υβριδικό μοντέλο είναι αρκετά
σύνθετο, αφού περιλαμβάνει τόσο
συντρέχοντα παραλληλισμό όσο και ρητή
επικοινωνία. Ακόμη, μπορεί να περιλαμβάνει
και SIMD προγραμματισμό των GPUs. Γίνονται
αρκετές προσπάθειες για την ανάπτυξη
ενός ενοποιμένου μοντέλου Υβριδικού
(Hybrid) ή Ετερογενούς (Heterogeneous)
παράλληλου προγραμματισμού.
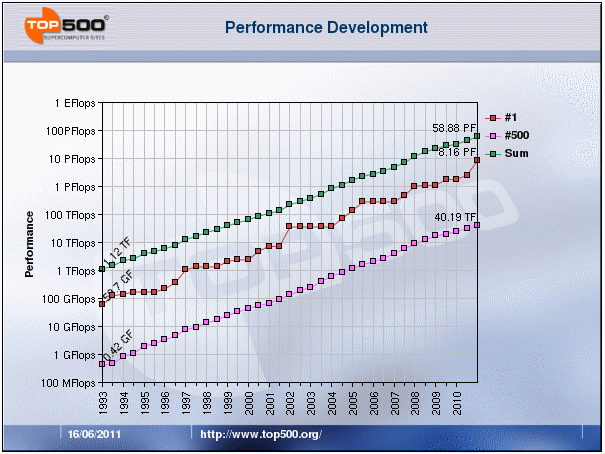
Πόσο γρήγορα είναι τα σημερινά
παράλληλα συστήματα; Ποιές είναι οι
βασικές αρχιτεκτονικές που χρησιμοποιούνται;
Διάφορα τέτοια ερωτήματα απαντιούνται
με ενημερωμένα στατιστικά στο Τop500
project. Εκεί μπορούμε να δούμε, για
παράδειγμα, ότι η συντρυπτική πλειονότητα
των σύγχρονων παράλληλων συστημάτων
ανήκουν στη κατηγορία τών Συστοιχιών
(Clusters). Οι κόμβοι των Συστοιχιών, επίσης
στη συντριπτική τους πλειοψηφία είναι
SMP's με Πολυπύρηνους Επεξεργαστές και
μάλιστα εμπορικά διαθέσιμοι, όχι δηλαδή
ειδικής κατασκευής. Πρόσφατα άρχισαν
να εισχωρούν κόμβοι που διαθέτουν
συνεπεξεργαστές GPU. Τα δίκτυα δισύνδεσης
είναι επίσης στη μεγάλη τους πλειοψηφία
Gigabit Ethernet ή ανάλογα, δηλαδή και πάλι
είναι εμπορικά διαθέσιμα και όχι ειδικής
κατασκευής.
Υποστήριξη Παράλληλου Προγραμματισμού
|
Ο προγραμματιστής
που θέλει να αναπτύξει μια εφαρμογή
παράλληλου προγραμματισμού πρέπει να
εξοικειωθεί με τις αναπόφευκτες αλλαγές
σε όλα τα επίπεδα του προγραμματισμού,
οι οποίες προκύπτουν από τη μετάβαση
από το ακολουθιακό στο παράλληλο
υπολογισμό. Τέτοιες αλλαγές υφίστανται,
σε διαφορετικό βαθμό, σε όλα τα επίπεδα
αφαίρεσης πάνω από την αρχιτεκτονική
των παράλληλων υπολογιστών: Στο
λειτουργικό σύστημα και το λογισμικό
συστήματος. στις γλώσσες προγραμματισμού
και στα συνοδευτικά εργαλεία, στα
μοντέλα προγραμματισμού και τη σχεδίαση
αλγορίθμων.
Εάν εξαιρέσουμε τα ειδικά συστήματα
(MPP's και NUMA μεγάλης κλίμακας), τα οποία
συνληθως χρησιμοποιούν ειδικό λογισμικό,
τα υπόλοιπα παράλληλα συστήματα
υποστηρίζονται από το λογισμικό ως
εξής:
Το τυπικό παράλληλο σύστημα
Μοιραζόμενης Μνήμης είναι CC-UMA (Πολυπύρηνο
SMP). Τα σύγχρονα λειτουργικά συστήματα
υποστηρίζουν πλήρως τέτοιες
αρχιτεκτονικές, οπότε δεν απαιτείται
επιπλέον λογισμικό. Επίσης, οι σύγχρονοι
compilers (σε ορισμένες περιπτώσεις με τη
βοήθεια κάποιων ειδικών αλλά ευρέως
διαθέσιμων βιβλιοθηκών) μπορούν να
παράγουν κατάλληλο κώδικα.
Το τυπικό παράλληλο
σύστημα Κατανεμημένης Μνήμης είναι
Cluster. Κάθε κόμβος του cluster έχει ένα
πλήρες λειτουργικό σύστημα, το οποίο
διασφαλίζει και τη δικτυακή επικοινωνία
μέσω TCP/IP. ΣΕπιπλέον, σε κάθε κόμβο
εγκαθίσταται και ειδικό ενδιάμεσο
λογισμικό (middleware) που εξασφαλίζει:
Ενιαία (Δικτυακή)
διαχείριση αρχείων σε όλους τους
κόμβους (πχ NFS) για διαχείριση δεδομένων
κλπ
Ταχύτερη επικοινωνία
με παράκαμψη ή ειδική διαχείριση του
πρωτοκόλλου TCP/IP
Σύστημα εκτέλεσης
(Run time system) και βιβλιοθήκες -επεκτάσεις
σε υπάρχουσες γλώσσες προγραμματισμού-
για τη μεταγλώττιση, μεταφορά και
εκτέλεση των παραλλήλων προγραμμάτων
Εργαλεία για συντονισμένη
διαχείριση, ενημέρωση και παρακολούθηση
του λογισμικού συστήματος των κόμβων.
Υπάρχουν ειδικές διανομές λειτουργικών
συστημάτων για Clusters, για παράδειγμα
Rocks, Oscar, Mosix κλπ. Εναλλακτικά η εγκατάσταση
μπορεί να γίνει απο μεμονωμένα πακέτα
λογισμικού. Συνήθως ένας από τπυς
κόμβους του Cluster έχει έναν ειδικό ρόλο
(front-end) και είναι αυτός που έχει
εγκατεστημένο το σύνολο του παραπάνω
λογισμικού ενώ οι υπόλοιποι κόμβοι
έχουν εγκατεστημένο μόνο ένα απαραίτητο
υποσύνολο. Επίσης μέσω του front-end συνήθως
διεξάγεται η επικοινωννία με τον 'έξω
κόσμο', με μονάδες μαζικής απόθήκευσης
δεδομένων κλπ.
Στην περίπτωση των συνεπεξεργαστών
GPU, τα λειτουργικά συστήματα προς το
παρόν δεν προσφέρουν σημαντική
υποστήριξη. Συνήθως απαιτείται η
εγκατάσταη καταλλήλων οδηγών (drivers)
για την επικοινωνία με το λειτουργικό
σύστημα. Για το προγραμματισμό απαιτείται
η χρήση ειδικών βιβλιοθηκών - ουσιαστικά
επεκτάσεων σε υπάρχουσες γλώσσες
προγραμματισμού. Τυπικά παραδείγματα
είναι το NVIDIA Cuda και η OpenCL.
Μοντέλα Παράλληλου Προγραμματισμού
|
Επισκόπιση
Τα μοντέλα παράλληλου
προγραμματισμού παρέχουν ένα επίπεδο
αφαίρεσης μεταξύ των παράλληλων
αλγορίθμων και των παράλληλων
αρχιτεκτονικών, ώστε να είναι δυνατή
η σχεδίαση και συγγραφή όσο το δυνατό
πιο ευέλικτου και μεταφερτού κώδικα.
Αν και ίσως δεν είναι
προφανές, τα μοντέλα προγραμματισμού
δεν συνδέονται άμεσα με συγκεκριμένες
αρχιτεκτονικές. Βέβαια, κάθε μοντέλο
υλοποιείται ευκολότερα σε κάποιες
αρχιτεκτονικές αλλά, θεωρητικά
τουλάχιστο, κάθε μοντέλο μπορεί να
υλοποιηθεί σε οποιαδήποτε αρχιτεκτονική.
Η χρήση ή επικράτηση κατά καιρούς
κάποιων μοντέλων συχνά σχετίζεται με
τη διαθέσιμη τεχνολογία και άλλες
συγκυριακές επιλογές.
Υπάρχουν αρκετά
μοντέλα παράλληλου προγραμματισμού,
τα επικρατέστερα είναι δύο:
Οι ενότητες που ακολουθούν περιγράφουν
τόσο τα δύο βασικά μοντέλα, όσο και
μερικά ακόμη, καθώς επίσης και μερικές
υλοποιήσεις τους.
Μοντέλα Παράλληλου Προγραμματισμού
|
Μοντέλο Διεργασιών
Το μοντέλο διεργασιών
ήταν μέχρι πρόσφατα το κύριο μοντέλο
ανάλυης του Συντρέχοντος (Concurrent)
προγραμματισμού και παραμένει βασικό
εργαλείο ανάπτυξης και ανάλυσης των
λειτουργικών συστημάτων. Στο μοντέλο
διεργασιών κάθε παράλληλη έργασία
(διεργασία) έχει ιδιωτικό χώρο λογικών
(εικονικών) διευθύνσεων που απεικονίζεται
σε ένα ενιαίο χώρο φυσικών διευθύνσεων,
με χρήση τεχνικών ιδεατής μνήμης.
Κάθε διεργασία έχει
ιδιωτικές μεταβλητές, ενώ η επικοινωνία
και ο συγχρονισμός των διεργασιών
επιτυγχάνεται με μηχανισμούς
διαδιεργασιακής επικοινωνίας, όπως
locks, semaphores, mutexes, monitors, pipes, message queues,
κοινόχρηστα αρχεία και ιδεατή μνήμη
κλπ.
Πλεονέκτημα του
μοντέλου είναι η ωριμότητά του και
ο σαφής διαχωρισμός του κώδικα των
εργασιών από τους μνηχανισμούς
επικοινωνίας και συγχρονισμού.
Μειονέκτημα του μοντέλου είναι η
σημαντική επιβάρυνση δημιουργίας και
διαχείρισης διεργασιών στα περισσότερα
λειτουργικά συστήματα, κάτι που λύνεται
με τη χρήση νημάτων .
Μοντέλα Παράλληλου Προγραμματισμού
|
Μοντέλο Νημάτων
Στο μοντέλο νημάτων,
κάθε διεργασία μπορεί να έχει πολλά
συντρέχοντα νήματα, δηλαδή ροές εντολών
που εκτελούνται έχοντας κοινό χώρο
λογικών διευθύνσεων αλλά ιδιωτική
στοίβα κλήσεων και κατάσταση επεξεργαστή.
Συχνά τα νήματα χαρακτηρίζονται ως
'ελαφρές' διεργασίες.
Ένας εναλλακτικός τρόπος περιγραφής
των νημάτων είναι ως συντρέχουσες
υπορουτίνες (co-routines) οι οποίες μπορούν
να εκτελεστούν σε ένα ή περισσότερους
επεξεργαστές. Στο παράδειγμα που
ακολουθεί: 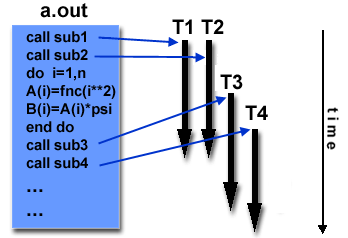
Το κύριο πρόγραμμα a.out
είναι μια κανονική διεργασία την οποία
διαχειρίζεται κατά τα γνωστά το
λειτουργικό σύστημα: δημιουργείται ο
περιγραφέας διεργασίας, ο χώρος λογικών
διευθύνσεων, οι συνδέσεις με αρχεία
και οι λοιποί αναγκαίοι πόροι του
συστήματος.
Το a.out δημιουργεί
σειραικά δύο νήματα (που φαίνονται σαν
κλήσεις ρουτινών sub1,
sub2), στη συνέχεια εκτελεί ένα
βρόχο for
και κατόπιν δημιουργεί δύο ακόμη
νήματα (που φαίνονται σαν κλήσεις
ρουτινών sub3,
sub4). Τα νήματα, όσο διαρκούνμ
μπορούν να εκτελούνται παράλληλα (ή
συνδρομικά).
Κάθε νήμα έχει δικές του τοπικές
μεταβλητές (ιδιωτική στοίβα κλήσεων)
αλλά έχει πρόσβαση σε καθολικά δεδομένα
της διεργασίας a.out., π.χ.
μεγάλες δομές δεδομένων, συναρτήσεις,
συνδέσεις με αρχεία κλπ (χώρος διευθύνσεων
και περιγραφέας διεργασίας). Επομένως
η δημιουργία και η συνδρομική διαχείριση
είναι λιγότερο δαπανηρές.
Τα νήματα επικοινωνούν μεταξύ τους
με λογικές διαδιεργασιακής επικοινωνίας.
Επομένως ισχύουν οι παρατηρήσεις που
αναφέρθηκαν στα μοντέλα διεργασιών
και μοιραζόμενης μνήμης.
Τα νήματα δημιουργούνται και
καταργούνται από το κύριο πρόγραμμα
a.out,
ενώ το κύριο πρόγραμμα είναι η μόνη
καθ' αυτό διεργασία η οποία έχει πλήρη
διάρκεια ζωής.
Υλοποιήσεις:
Και
στις δύο περιπτώσεις ο προγραμματιστής
είναι υπεύθυνος για τον καθορισμό του
παραλληλισμού. Το σύστημα εκτέλεσης
της εφαρμογής μπορεί να συμμετέχει στη
διαχείριση (User Level Threads) ή
εναλλακτικά η διαχείριση γίνεται εξ'
ολοκλήρου από το λειτουργικό σύστημα
(Kernel Level Threads). Στη περίπτωση των
User Level Threads, μπορεί απλά να έχουμε
τυπική συντρέχουσα επεξεργασία σε
επίπεδο εικονικής ή φυσικής μηχανής.
Στη περίπτωση των Kernel Level Threads, η
εφαρμογή μπορεί να εκτελεστεί συνδρομικά
ή παράλληλα, ανάλογα με τη φυσική μηχανή
που διαχειρίζεται ο πυρήνας.
Οι πολυνηματικές εφαρμογές, καθώς
και οι υλοποιήσεις νημάτων σε επίπεδο
επεξεργαστή, έχουν ξεκινήσει εδώ και
αρκετά χρόνια. Όμως οι υλοποιήσεις ήταν
πολύ διαφορετικές μεταξύ τους με
αποτέλεσμα να μην υπάρχει προτυποποίηση
και μεταφέρσιμος κώδικας.
Οι προσπάθειες προτυποποίησης
οδήγησαν σε δύο διαφορετικές αλλά
σχετιζόμενες υλοποιήσεις νημάτων:
POSIX Threads και OpenMP.
POSIX Threads
Βιβλιοθήκη συναρτήσεων,
απαιτούν κλήσεις συναρτήσεων με αρκετά
σύνθετη σύνταξη.
Προτυποποίηση με
το πρότυπο IEEE POSIX 1003.1c standard (1995), βλ.
www.opengroup.org
Διαθέσιμη μόνο σε
γλώσσα C.
Συνήθως αναφέρονται
ως Pthreads.
Οι περισσότεροι
επεξεργαστές και λειτουργικά συστήματα
διαθέτουν διεπαφές προγραμματισμού
σε Pthreads προσφέροντας το χαμηλότερο
δυνατό επίπεδο μεταφέρσιμου
προγραμματισμού νημάτων.
Εντελώς ρητός και λεπομερής
παραλληλισμός, γι' αυτό και απαιτεί
μεγάλη προσοχή από το προγραμματιστή.
OpenMP
Βιβλιοθήκη που
καλείται μέσω Οδηγιών Μεταγλωττιστή
που μορούν να ενσωματωθούν και σε
ακολουθιακό κώδικα.
Προτυποποίηση από
κατασκευαστές υλικού και λογισμικού,
βλ. OpenMP.org
Διαθέσιμη σε Fortran
και C/C++ (1997 και 1998 αντίστοιχα).
Μεταφέρσιμη υλοποίηση
νημάτων, καλύπτει λειτουργικά συστήματα
βασισμένα στο Unix και στα MS-Windows.
Εύκολος και απλός προγραμματισμός,
μπορεί να εφαρμοστεί σε διαδοχικά
βήματα βελτίωσης του κώδικα (incremental
parallelism). Στην ουσία οι οδηγίες στο
μεταγλωττιστή αναλύονται σε κώδικα
POSIX Threads, διευκολύνοντας έτσι τον
προγραμματισμό με νήματα.
Σταδιακά, με την
επικράτηση των πολυπύρηνων επεξεργαστών,
οι περισσότερες γλώσσες προγραμματισμού
ενισχύονται με βιβλιοθήκες και ΑPI
πολυνηματικού προγραμματισμού. Για
παράδειγμα η Microsoft έχει παρουσιάσει τη
Τask Parallel Library (ΤPL) για τη C#, η Intel τα Thread
Building Blocks (TBB) και Cilk++, η Java διαθέτει Java
Threads, κλπ. Επίσης υπάρχουν αρκετές άλλες
δημόσια διαθέσιμες βιβλιοθήκες. Οι
λεπτομέρειες διαφέρουν αλλά η
λειτουργικότητα παραμένει παρόμοια.
Ο SIMD προγραμματισμός των GPUs ακολουθεί
και αυτός το μοντέλο των νημάτων, με
ορισμένες βασικές διαφοροποιήσεις. Ο
αριθμός των δημιουργούμενων νημάτων
είναι πολύ μεγαλύτερος από οτι στις
περιπτώσεις του MIMD προγραμματισμού
αλλά τα νήματα εκτελούν απλούστερες
κανονικές λειτουργίες σε 'τοπικά'
δεδομένα. Τα νήματα είναι οργανωμένα
σε ομάδες οι οποίες έχουν γρήγορη
πρόσβαση σε συγκεκριμένη περιοχή
μνήμης, ενώ η επικοινωνία με άλλες ομαες
νημάτων είναι δαπανηρή.
Μοντέλα Παράλληλου Προγραμματισμού
|
Μοντέλο Μεταβίβασης Μηνυμάτων
Υλοποιήσεις:
Από την άποψη του προγραμματισμού,
το μοντέλο μεταβίβασης μηνυμάτων
συνήθως υλοποιείται ως ένα σύνολο
συναρτήσεων βιβλιοθήκης. Ο προγραμματιστής
καθορίζει τον παραλληλισμό με κλήσεις
των συναρτήσεων μέσα στο πρόγραμμα.
Από τη δεκαετία του 1980 υπήρχαν
αρκετές υλοποιήσεις μεταβίβασης
μηνυμάτων, οι οποίες διέφεραν πολύ
μεταξύ τους ώστε δεν υπήρχε δυνατότητα
ανάπτυξης μεταφέρσιμων εφαρμογών.
Το 1992, δημιουργήθηκε το MPI Forum με
κύριο στόχο την δημιουργία μιας πρότυπης
διεπαφής για τις υλοποιήσιες μεταβίβασης
μηνυμάτων.
H Διεπαφή Μεταβίβασης Μηνυμάτων
(Message Passing Interface, MPI) δημοσιεύτηκε το
1994. Μια νέα έκδοση (MPI-2) δημοσιεύτηκε το
1996. Και τα δύο πρότυπα διατίθενται στον
ιστοτόπο www.mcs.anl.gov/Projects/mpi/standard.html.
Το MPI είναι πλέον το "de facto"
πρότυπο μεταβίβασης μηνυμάτων,
αντικαθιστώνταν όλες τις άλλες
υλοποιήσεις. Σχεδόν όλοι οι κατασκευαστές
παράλληλων συστημάτων παρέχουν
υλοποιήσεις του MPI, ενώ μερικοί παρέχουν
και του MPI-2. Οι πιο γνωστές είναι αυτές
του Mpich και του OpenMPI.
To MPI εφαρμόζεται και σε αρχιτεκτονικές
μοιραζόμενης μνήμης,όπου η μεταβίβαση
μηνυμάτων υλοποιείται μέσω κοινής
μνήμης, μια τεχνική που θυμίζει τα
message queues του μοντέλου διεργασιών. Με
αυτή την έννοια το μοντέλο μεταβίβασης
μηνυμάτων είναι λογικά ισοδύναμο προς
το μοντέλο των νημάτων και επιτρέπει
την κοινή αντιμετώπιση του προγραμματισμού
συστημάτων Μοιραζόμενης και Κατανεμημένης
Μνήμης. Όμως, τουλάχιστο προς το παρόν,
το
MPI διαχειρίζεται μόνο διεργασίες,
όποτε όταν απαιτείται διαχείριση
νημάτων η χρήση αντίστοιχου εργαλείου
(πχ OpenMP είναι απαραίτητη).
Μοντέλα Παράλληλου Προγραμματισμού
|
Υβριδικό Μοντέλο
Σε αυτό το μοντέλο έχουμε το συνδυασμό
δύο ή περισσότερων από τα προηγούμενα
μοντέλα.
Το πιό κοινό παράδειγμα είναι ο
συνδυασμός της μεταβίβασης μηνυμάτων
(MPI) με το μοντέλο νημάτων (POSIX threads ή
OpenMP). Το μοντέλο αυτό αποκτά ιδιαίτερη
σημασία λόγω της επέκτασης των υβριδικών
παράλληλων αρχιτεκτονικών, δηλαδή
δικτυωμένων πολυπήρυνων συστημάτων.
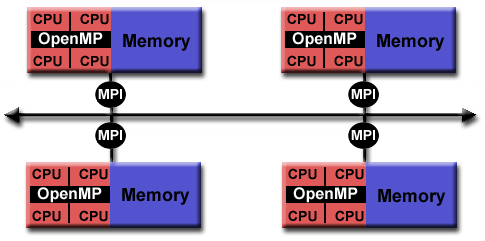
Ανάλογα παραδείγματα είναι ο
συνδυασμός είναι ο συνδυασμός OpenMP με
CUDA ή MPI με CUDA. Ακόμη θα μπορούσαμε να
έχουμε την συνύπαρξη και των τριών
ΑPIs, δηλαδή MPI, OpenMP και CUDA. Γίνεται
προσπάθεια μέσω τoυ OpenCL και αλλων ΑPIs
να επιτρέπεται η κοινή ανάπτυξη κώδικα
για CPUs και GPUs.
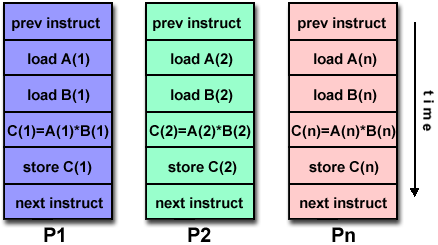
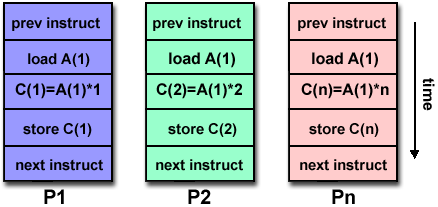
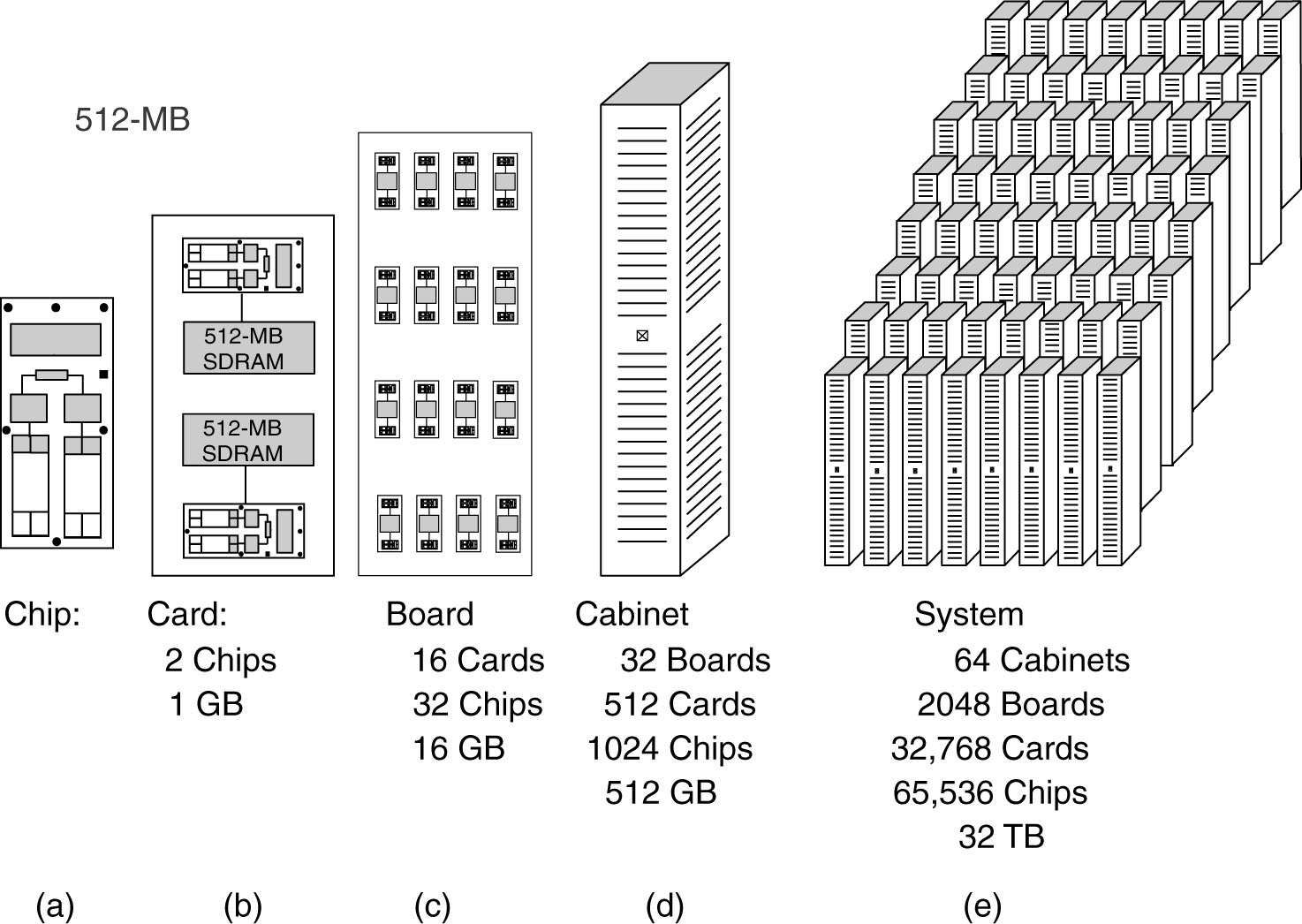
Ανάπτυξη Παράλληλων Προγραμμάτων
|
Απλό Πρόγραμμα Πολλαπλά Δεδομένα
(Single Program Multiple Data, SPMD):
Σε ένα τυπικό σύστημα Μοιραζόμενης
Μνήμης το παράλληλο πρόγραμμα αναπτύσσεται
και μεταγλωττίζεται στη κοινή (κεντρική)
μνήμη του συστήματος. Άρα εξ'ορισμού
υπάρχει ένα αντίγραφο του εκτελέσιμου
προγράμματος το οποίο εκτελείται στον
ενιαίο χώρο διευθύνσεων της Μοιραζόμενης
Μνήμης. Τα νήματα που υλοποιούν τις
παράλληλες εργασίες δημιουργούνται,
εκτελούνται και τερματίζονται μέσα σε
αυτό τον ενιαίο χώρο διευθύνσεων.
Συνήθως τα νήματα επεξεργάζονται
διαφορετικά (από τα μοιραζόμενα) δεδομένα
ή εκτελούν διαφορετικές λειτουργίες.
Η γλώσσα προγραμματισμού αλλά και το
περιβάλλον εκτέλεσης πρέπει να έχει
ένα μηχανισμό ονομασίας (ή αρίθμησης)
των νημάτων έτσι ώστε να υπάρχει έλεγχος
ως προς το ποιό νήμα εκετελείται σε
ποιά CPU, ποιά δεδομένα επεξεργάζεται
ή/και ποιά λειτουργία εκτελεί. ίδιος
μηχανισμός ταυτοποίησης των νημάτων
είναι απαραίτητος για την επικοινωνία
μεταξύ των νημάτων.
Σε ένα τυπικό Σύστημα Κατανεμημένης
Μνήμης το παράλληλο πρόγραμμα αναπτύσσεται
σε έναν υπολογιστή (συνήθως το front-end
του Cluster) αλλά εκτελείται σε πολλούς
κόμβους, με το καθένα να έχει τη δική
του τοπική μνήμη, άρα το δικό του χώρο
διευθύνσεων και τα δικά του τοπικά
δεδομένα (Κατά κύριο λόγο. Μπορεί να
επιτρέπεται προσπέλαση σε κοινόχρηστα
αρχεία π.χ για την αρχική πρόσκτηση ή
τη τελική αποθήκευση δεδομένων, αλλά
η κύρια επεξαργασία γίνεται στη τοπική
μνήμη του κάθε κόμβου). Σε αυτή τη
περίπτωση το προς εκτέλεση παράλληλο
πρόγραμμα πριν εκτελεστεί πρέπει να
αντιγραφεί στις τοπικές μνήμες των
κόμβων. Συνήθως υπάρχει το ίδιο πρόγραμμα
για όλους τους κόμβους, όμως η γλώσσα
προγραμματισμού και το περιβάλλον
εκτέλεσης πρέπει να έχουν ένα μηχανισμό
ο ονομασίας (ή αρίθμησης) ώστε κάθε
κόμβος να γνωρίζει τα δεδομένα που θα
επεξεργαστεί ή και τη λειτουργία που
θα εκτελέσει. Ο ίδιος μηχανισμός είναι
απαραίτητος και για την επικοινωνία
μεταξύ των εργασιών (ή καλύτερα των
κόμβων που εκτελούν κάποια παράλληλη
εργασία).
Η μέθοδος σχεδιασμού και ανάπτυξης
ενός παραλλήλου προγράμαματος που
περιγράφηκε λέγεται Απλό Πρόγραμμμα
Πολλαπλά Δεδομένα (Single Program Multiple Data,
SPMD). Πιο σωστά ίσως θα έπρεπε να
λέγεται Απλό Πρόγραμμα Πολλαπλά Δεδομένα
ή/και Λειτουργίες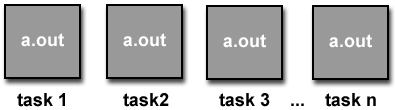
Τα προγράμματα SPMD ενσωματώνουν
εντολές (κλήσεις βιβλιοθήκης) που
επιτρέπουν τις εργασίες να αναγνωρίζουν
την ταυτότητά τους ώστε να εκτελούν το
αντίστοιχο τμήμα προγράμματος
if
(myid == ...) then {...} else {...}
Ετσι εκτελείται
το ίδιο πρόγραμμα, όχι όμως αναγκαστικά
η ίδια λειτουργία (δηλαδή το ίδιο
υποπρόγραμμα), από όλες τις εργασίες.
Επίσης κάθε εργασία επίσης μπορεί να
επεξεργάζεται διαφορετικά υποσύνολα
δεδομένων.
Ανάπτυξη Παράλληλων Προγραμμάτων
|
Αυτόματη Παραλληλοποίηση
Ο σχεδιασμός και η
ανάπτυξη παράλληλων προγραμμάτων είναι
παραδοσιακά χειρωνακτική και σύνθετη
διαδικασία. Συνήθως ο προγραμματιστής
είναι υπεύθυνος για να αντιληφθεί, να
σχεδιάει και να υλοποιήσει το παραλληλισμό.
Πολύ συχνά, η
χειρωνακτική ανάπυξη παράλληλου
προγράμματος είναι μια διαδικασία
χρονοβόρα, σύνθετη, επιρρεπής σε σφάλματα
και επαναληπτική.
Εδώ και αρκετά χρόνια,
διατίθενται διάφορα εργαλεία υποβοήθησης
του προγραμματιστή για την αυτόματη
μετατροπή ορισμένου τύπου ακολουθιακών
προγραμμάτων σε παράλληλα. Οι γνωστότεροι
τύποι εργαλείων είναι οι parallelizing
compilers και οι pre-processors.
O parallelizing compiler λειτουργεί με δυο
διαφορετικούς τρόπους:
Η αυτόματη ή
ημι-αυτόματη παραλληλοποίηση είναι
γρήγορη και σχετικά εύκολη μέθοδος
αλλά έχει σημαντικά προβλήματα:
Τα αποτελέσματα
μπορεί να είναι εσφαλμένα και ο
προγραμματιστής να μην είναι σε θέση
να αντιληφθεί γιατί, αφού ο τελικά
παραγόμενος κώδικας δεν είναι υπό τον
πλήρη έλεγχό του
Αντίστοιχα ισχύουν
για τον έλεγχο απόδοσης του προγράμματος:
η εύρεση των προβληματικών σημείων
απαιτεί πλήρη γνώση του κώδικα
Η παραπέρα τροποίηση
και συντήρηση του κώδικα είναι δύσκολη
Συνήθως είναι
επιτυχής σε παραλληλοποίηση απλών
σχετικά βρόχων, αλλά όχι σε σύνθετο
κώδικα, με εξαρτήσεις και διακλαδώσεις
Τα περισσότερα
εργαλεία είναι διαθέσιμα σε Fortran
Στη συνέχεια θα ασχοληθούμε με την
χειρωνακτική παραλληλοποίηση εφαρμογών.
Σχεδιασμός Παράλληλων Προγραμμάτων
|
Κατανόηση του Αλγορίθμου
και του Προγράμματος
Αναμφισβήτητα το
πρώτο βήμα στην ανάπτυξη παράλληλου
λογισμικού είναι η κατανόηση του
προβλήματος και του αλγορίθμου επίλυσης.
Επίσης, αν υπάρχει ακολουθιακός κώδικας,
πρέπει και αυτός να γίνει πλήρως
κατανοητός.
Πριν αρχίσουμε την ανάπτυξη της
παράλληλης λύσης πρέπει να αποφασίσουμε
αν ο αλγόριθμος (ή το πρόγραμμα)
παραλληλοποιείται.
Παράδειγμα Παραλληλοποιήσιμου
Προβλήματος (Χρόνος):
Μελέτη
Παραμέτρων (Parameter Study): Υπολόγισε
τη τιμή μιας σύνθετης συνάρτησης για
κάθε ένα από πολλές χιλιάδες
ανεξάρτητους συνδυασμούς μεταβλητών
εισόδου. Στη συνέχεια υπολόγισε την
μέγιστη (ή ελάχιστη ή μέση) τιμή.
|
Αυτός ο τύπος προβλήματος είναι πολύ
διαδεδομένος και έχει προφανή ή φυσικό
(natural) παραλληλισμό (συνηθίζεται
και η έκφραση Embarrassingly Paralell): κατ'
αρχήν κάθε στιγμιότυπο του προβλήματος
μπορεί να επιλυθεί ανεξάρτητα από τα
υπόλοιπα, ενώ στο τέλος απαιτείται μια
αναγωγή ή άλλη σύνθεση των επιμέρους
αποτελεσμάτων, πράγμα το οποίο μοπρεί
να γίνει και αυτό εν μέρει παράλληλα,
αφού υπάρχει η δυνατότητα επιμερισμού
της αναγωγής και σταδιακής σύνθεσης
του αποτελέσματος.
Παράδειγμα Παραλληλοποιήσιμου
Προβλήματος (Χώρος):
Παραλληλισμός
Δεδομένων (Data Parallelism): Υπολόγισε
τη τιμή μιας σειράς παραμέτρων
για κάθε ένα (ή μια ομάδα) από πολλές
χιλιάδες ανεξάρτητα στοιχεία μιας
δομής δεδομένων, για παράδειγμα τη
ταύτιση ενός προτύπου σε μια βάση
DNA.
|
Και αυτός ο τύπος προβλήματος είναι
πολύ διαδεδομένος και έχει προφανή ή
φυσικό (natural) παραλληλισμό: κάθε
στοιχείο ή ομάδα στοιχείων μπορεί να
υποστεί επεξεργασία ανεξάρτητα από
τα υπόλοιπα, ενώ στο τέλος μπορεί να
απαιτείται μια αναγωγή ή άλλη σύνθεση
των επιμέρους αποτελεσμάτων.
Παράδειγμα Μη-Παραλληλοποιήσιμου
Προβλήματος (Επαναληπτική Εξάρτηση):
Υπολογισμός της σειράς Fibonacci
(1,1,2,3,5,8,13,21,...) στη μορφή:
F(k + 2) = F(k + 1) + F(k)
|
Αυτό το πρόβλημα είναι μη-παραλληλοποιήσιμο
γιατί ο υπολογσιμός του όρου k + 2 υποθέτει
την ύπαρξη των όρων k + 1 και k, οι οποίοι
δεν μπορούν να υπολογιστούν ανεξάρτητα
(δηλαδή παράλληλα). Αυτός ο περιορισμός
ισχύει γενικά για επαναληπτικές
(iterative) διαδικασίες, όπου το επόμενο
βήμα υποθέτει τη χρήση του προηγούμενου.
Παράδειγμα Ατελώς-Παραλληλοποιήσιμου
Προβλήματος (Δομική Εξάρτηση):
Επεξεργασία μιας δομής δεδομένων με
αυστηρή σειρά, π.χ. η επεξεργασία μιας
συνδεδεμένης λίστας
|
Αυτό το πρόβλημα είναι
ημι-παραλληλοποιήσιμο γιατί η πρόσθεση
ή αφαίρεση ενός κόμβου δεν μπορεί να
γίνει παράλληλα (ταυτόχρονα) με άλλη
τέτοια ενέργεια αφού θα επηρρεάσει
την ακεραιότητα της δομής. Απαιτείται
'κλείδωμα' (lock) της ενέργειας,
άρα αναγκαστική σειριοποίηση των
παράλληλων εργασιών.
Εύρεση των θερμών
σημείων (hotspots) του προγράμματος:
Βρίσκουμε τα πιο
χρονοβόρα τμήματα του προγράμματος
(CPU time, όχι Ι/Ο ή επικοινωνία), συνήθως
βρόχοι.
Η χρήση profiler και
optimizer μπορεί να βοηθήσει στην
αυτοματοποίηση της διαδικασίας.
Εστιάζουμε στα θερμά σημεία και
αφήνουμε τα υπόλοιπα τμήματα του
προγράμματος για παραπέρα βελτιώσιες.
Εύρεση των σημείων
συμφόρησης (bottlenecks) του προγράμματος:
Προσπαθούμε να
αντιληφθούμε εάν μέσα στα θερμά σημεία
υπάρχουν τμήματα κώδικα που προκαλούν
δυσανάλογες καθυστερήσεις. Για
παράδειγμα η αναίτια ενσωμάτωση I/O σε
ένα βρόχο υπολογισμών ή η υπερβολικές
αναφορές στη μνήμη για τον υπολογισμό
εκφράσεων ή οι υπερβολικά σύνθετες
εκφράσεις είναι σημεία που μπορούν να
επιβραδύνουν το πρόγραμμα.
Ίσως απαιτεηθεί αναδόμηση του
προγράμματος ή αλλαγή αλγορίθμου για
την ελαχιστοποίηση των σημείων
συμφόρησης.
Εύρεση των εμποδίων παραλληλισμού.
Το συχνότερο εμπόδιο είναι η επαναληπτική
ή δομική εξάρτηση δεδομένων (data
dependencies), όπως αναλύθηκε παραπάνω.
Διερεύνηση εναλλακτικών αλγορίθμων:
πολλές φορές είναι το σημαντικότερο
ζήτημα. Πολύ συχνά απλούστεροι, και
λιγότερο αποδοτικοί, ακολουθιακοί
αλγόριθμοι παρουσιάζουν μεγαλύτερες
δυνατότητες παραλληλισμού από ότι
αλγόριθμοι που χρησιμοποιούν σύνθετες
δομές δεδομένων ή περίτεχνους υπολογισμούς
με περίπλοκες εξαρτήσεις δεδομένων.
Η πιο γνωστή μεθοδολογία σχεδίασης
παράλληλων αλγορίθμων, η οποία επιτρέπει
τη συστηματική διερεύνηση των πολλαπλών
εναλλακτικών λύσεων είναι αυτή του Ian
Foster που αναπτύχθηκε στο βιβλίο του
Designing
and Building Parallel Programs. (Στο σύνδεσμο που
δίνεται υπάρχει και Ελληνική απόδοση
ορισμένων τμημάτων του βιβλίου που
αφορούν τη σχεδίαση παράλληλων αλγορίθμων
και την μέτρηση απόδοσης παράλληλων
προγραμμάτων).
Σχεδιασμός Παράλληλων Προγραμμάτων
|
Επιμερισμός
Συνήθως το πρώτο
βήμα σχεδιασμού ενός παράλληλου
προγράμματος είναι ο επιμερισμός,
δηλαδή ο λογικός χωρισμός του υπολογιστικού
έργου σε επιμέρους υποέργα, αυτά που
θα υλοποιούν οι παράλληλες εργασίες.
Αυτό το βήμα ονομάζεται επιμερισμός ή
καταμερισμός.
Υπάρχουν δύο βασικές μέθοδοι
επιμερισμού: επιμερισμός δεδομένων
(domain decomposition) και επιμερισμός
λειτουργιών (functional decomposition).
Επιμερισμός Δεδομένων:
Οι δομές δεδομένων του προβλήματος
χωρίζονται σε τμήματα. Κάθε παράλληλη
εργασία επεξεργάζεται ένα ή περισσότερα
τμήματα.
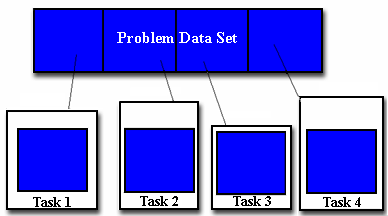
Τα δεδομένα μπορούν
να επιμεριστούν με διάφορους τρόπους.
Μονοδιάστατα, δι-διάστατα ή πολυδιάστατα,
σε γραμμές, στήλες ή blocks, με αδρομερή ή
λεπτομερή κοκκιότητα.Συνήθως η αδρομερής
κοκκιότητα επιτρέπει ευκολότερο
προγραμματισμό αλλά επιβάλλει στατική
κατανομή των δεδομένων ενώ η
λεπτομερής κοκκιότητα επιτρέπει
δυναμική κατανομή δεδομένων
σε περίπτωση ανισορροπιών στους
υπολογισμούς.

Ο επιμερισμός δεδομένων είναι
αρκετά εμφανής στις περιπτώσεις φυσικού
παραλληλισμού (στο χρόνο ή στο χώρο).
Στη γενικότερη περίπτωση όμως ο
επιμερισμός δεδομένων μπορεί να
περιλαμβάνει επικάλυψη των ορίων ή και
ενδιάμεση επικοινωνία μεταξύ των
εργασιών, δηλαδή τα δεδομένα μπορεί να
μην είναι εντελώς ανεξάρτητα μεταξύ
τους. Παραδείγματα επικάλυψης ορίων:
αναζήτηση προτύπων ή επεξεργασία
εικόνας. Παραδείγματα ενδιάμεσης
επικοινωνίας και συγχρονισμού:
επαναληπτικοί υπολογισμοί πινάκων με
έλεγχο σύγκλισης.
Επιμερισμός Λειτουργιών:
Εδώ ο επιμερισμός εστιάζεται στα
λογικά τμήματα του προγράμματος
(υπο-προγράμματα) αντί για τα δεδομένα.
Ένα ή περισσότερα υπο-προγράμματα
αποτελούν μια εργασία.
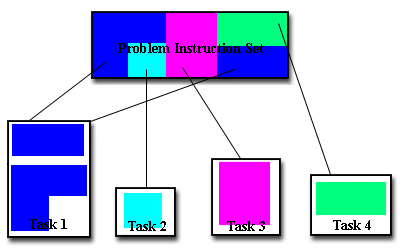
Συχνά απαιτείται ο συνδυασμός των
δύο μεθόδων επιμερισμού. Για παράδειγμα,
κάθε τμήμα του μοντέλου του κλίματος
μπορεί να περιέχει επιμερισμό δεδομένων:
η ατμόσφαιρα πχ συνήθως μοντελοποιείται
ως τρισδιάστατο αέριο με διαφορετικά
χαρακτηριστικά ανάλογα με το ύψος ή
την επιφάνεια του εδάφους. Επιπλέον,
μπορούμε να έχουμε πολλά διαφορετικά
κλιματικά μοντέλα, αν μεταβάλλουμε
ορισμένες παραμέτρους, όπως πχ η εξέλιξη
της θερμοκρασίας της θάλασσας ή η
συσώρευση αερίων θερμοκηπίου στην
ατμόσφαιρα.
Συντονιστής - Εργαζόμενοι (Master - Workers):
Η ευκολότερη ίσως μεθοδολογία
σχεδιασμού παράλληλων προγραμμάτων
που βασίζονται στη λογική του επιμερισμού
λειτουργιών και βασίζεται στο μοντέλο
υψηλού επιπέδου SPMD είναι η μεθοδολγία
που ονομάζεται Συντονιστής - Εργαζόμενοι.
Το πρόγραμμα αποτελείται από ένα σύνολο
υπο-ρουτινών, χονδρικά μια υπο-ρουτίνα
για κάθε παράλληλη εργασία. Όλοι οι
επεξεργαστές εκτελούν το ίδιο εκτελέσιμο
αλλά εκτελούν τμήμα του, ανάλογα με τη
ταυτότητά τους (SPMD). Μια παράλληλη
εργασία (νήμα ή διεργασία) θεωρείται
ως Συντονιστής (Master Thread / Process). Eίναι
υπεύθυνη για την επικοινωνία με το
χρήστη, την αρχικοποίηση και διανομή
των δεδομένων ή συντονισμό λειτουργιών
στις υπόλοιπες παράλληλες εργασίες
που παίζουν το ρόλο των Εργαζόμενων.
Επίσης είναι υπεύθυνη για τη τελική
συλλογή και παρουσίαση των αποτελεσμάτων.
Οι υπόλοπες εργασίες εκτελούν το τμήμα
του προγράμματος που τις αφορά. Στην
απλούστερη περίπτωση εκτελούν το ίδιο
πρόγραμμα αλλά σε διαφορετικά δεδομένα
(επιμερισμός δεδομένων), μπορεί όμως
να εκτελούν και διαφορετικές λειτουργίες
(επιμερισμός λειτουργειών). Το μοντέλο
Συντονιστής-Εργαζόμενοι όταν αναφέται
στη διανομή δεδομένων αρκετά συχνά
λαμβάνει τη μορφή Διανομή-Υπολογισμός-Συλλογή
(Distribute-Compute-Aggregate, DCA). Επιπλέον,
αυτή η διδικασία DCA μπορεί να έχει
επαναληπτική μορφή με ενδιάμεσα βήματα
συγχρονισμού, τοπικού ή γενικού.
Δεξαμενή Εργασιών (Pool of Tasks):
Τόσο στον επιμερισμό δεδομένων όσο
και στον επιμερισμό λειτουργιών η
διανομή των δεδομένων ή των λειτουργιών
μπορεί να είναι είτε στατική ή δυναμική.
Δηλαδή τόσο τα δεδομένα όσο και οι
λειτουργίες μπορεί να επιμερίζονται
σε διαδοχικές φάσεις κατά τις οποίες
ο επιμερισμός να είναι διαφορετικός,
δηλαδή να έχει μια μορφή αναδρομικού
ή εντελώς δυναμικού επιμερισμού.
Επιπλέον το πλήθος των δεδομένων ή
λειτουργιών του προγράμματος μπορεί
να είναι μεταβλητός, δηλαδή το πρόγραμμα
κατά την εκτέλεσή του να δημιουργεί
νέα δεδομένα ή λειτουργίες, τα οποία
πρέπει να αναδιανεμηθούν στις παράλληλες
εργασίες προς επεξεργασία. Το μοντέλο
αυτό συνήθως ονομάζεται Δεξαμενή
Εργασιών (Pool of Tasks).
Σχεδιασμός Παράλληλων Προγραμμάτων
|
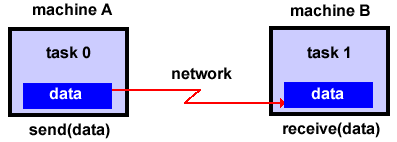
Επικοινωνία
Γιατί Επικοινωνίες;
Η απαίτηση για επικοινωνίες εξαρτάται
από το τύπο του προβλήματος:
ΔΕΝ απαιτούνται
επικοινωνίες
Αρκετοί τύποι προβλημάτων μπορούν
να παραλληλοποιηθούν με ελάχιστο
διαμοιρασμό δεδομένων ή και ελάχιστη
επικοινωνία μεταξύ των εργασιών. Τυπικά
παραδείγματα είναι η πλειοψηφία των
εφαρμογών φυσικού παραλληλισμού:
Σε μια εικόνα, η επεξεργασία που
υφίσταται ένα pixel μπορεί να μην εξαρτάται
από τα γειτονικά, έτσι η εικόνα μπορεί
να επιμεριστεί σε εργασίες χωρίς
πρόβλημα επικοινωνίας, παρά μόνο ίσως
στα σύνορα των τμημάτων της εικόνας.
Αντίστοιχα, το σπάσιμο ενός κρυπτογραφημένου
κειμένου μπορεί να γίνει με δοκιμή
διαφορετικών κλειδιών ή μεθόδων, χωρίς
επικοινωνία μεταξύ των εναλλακτικών
λύσεων.
ΑΠΑΙΤΟΥΝΤΑΙ
επικοινωνίες
Οι πιο σύνθετοι
τύποι προβλημάτων συνήθως περιέχουν
κάποια μορφή εξάρτησης δεδομένων ή
συγχρονισμού. Σε αυτή τη περίπτωση
απαιτείται επικοινωνία, είτε απλά για
συχγρονισμό επαναλήψεων ή/και για
ανταλλαγή δεδομένων. Για παράδειγμα,
ένα μοντέλο θερμικής διάχυσης στο χώρο
ή ένα μοντέλο ρευστοδυναμικής απαιτεί
επικοινωνία μεταξύ των γειτονικών
σημείων ώστε να υπολογιστούν οι τιμές
των παραμέτρων σε όλο το μοντέλο. Επίσης
επειδή το μοντέλο εξελίσσεται στο
χρόνο, απαιτείται και συγχρονισμός
μεταξύ διαδοχικών υπολογισμών στο
ίδιο σημείο.
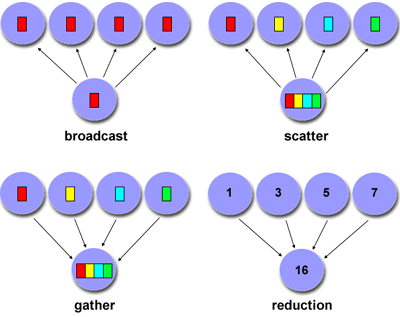
Πρότυπα επικοινωνιών
Ήδη έχουμε συζητήσει έμμεσα ένα
πρότυπο επικοινωνίας, το
Διανομή-Υπολογισμός-Συλλογή, που παρέχει
ένα ελάχιστο επικοινωνιακό πρότυπο.
Οι παράλληλες εργασίες - Εργαζόμενοι
επικοινωνούν μόνο με την παράλληλη
εργασία - Συντονιστή στην αρχική διανομή
και τελική συλλογή δεδομένων. Προφανώς
μπορεί να υπάρχουν πολύ πιο σύνθετα
παραδείγματα επικοινωνιών, μερικά από
τα οποία φαίνονται παρακάτω:
- Επεξεργασία Σήματος
-
Ένα ηχητικό σήμα περνά μέσα από τέσσερα
υπολογιστικά φίλτρα. Κάθε φίλτρο
υλοποιείται σαν ξεχωριστή εργασία.
Κάθε τμήμα τπυ σήματος πρέπει να περάσει
διαδοχικά από όλα τα φίλτρα, έτσι ώστε
δημιουργείται μια μονόδρομη επικοινωνία
'γειτονικών' εργασιών (Διοχέτευση).
-
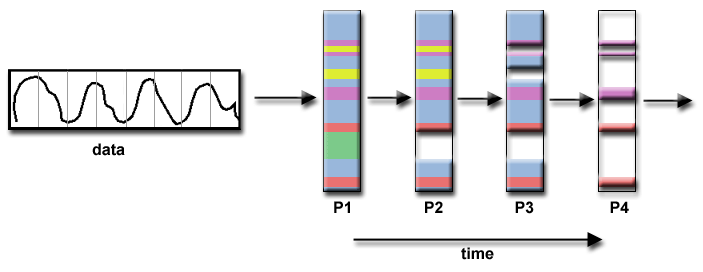
Μοντελοποίηση Οικοσυστήματος
Κάθε πρόγραμμα
υπολογίζει τον πληθυσμό ενός διαφορετικού
είδους, όπου η εξέλιξη του πληθυσμού
ενός είδους εξαρτάται από την εξέλιξη
των γειτονικών πληθυσμών. Σε κάθε χρονική
στιγμή, μια εργασία υπολογίζει τη
τρέχουσα κατάστασή της, ανταλλάσσει
πληροφορίες με τους γείτονες και
συνεχίζει στην επόμενη χρονική στιγμή.
Αμφίδρομη επικοινωνία μεταξύ 'γειτονικών'
παράλληλων εργασιών.
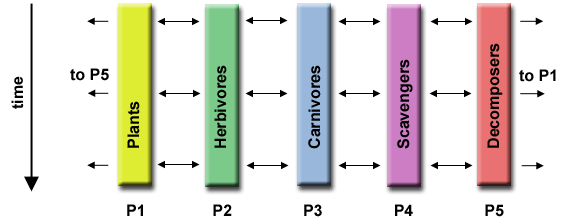
-
Μοντελοποίηση Κλίματος
-
Έχουμε τέσσερα διαφορετικά αλληλεπιδρώντα
τμήματα: το μοντέλο ατμόσφαιρας, το
μοντέλο θαλασσών, το μοντέλο εδάφους
και το μοντέλο υπογείων και επιγείων
υδάτων. Η αλληλεπίδραση είναι ιδιαίτερα
σύνθετη και διαρκής, βραχυπρόθεσμη
αλλά και μακροπρόθεσμη, άρα υπάρχει
και χρονική εξάρτηση.Εδώ έχουμε ένα
ιδιαίτερο (ad hoc) μοντέλο επικοινωνίας.
-
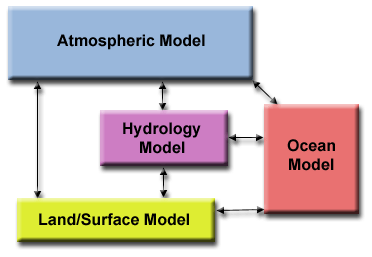
-
Πιο σύνθετα μοντέλα επικοινωνίας
περιλαμβάνουν δι-διάστατη επιοινωνία,
επικοινωνία σε μορφή δένδρου, επικοινωνίες
που το πρότυπό τους μεταβάλλεται ανάλογα
με το στάδιο υπολογισμού κλπ.
Παράγοντες σχεδιασμού επικοινωνίας:
Υπάρχουν αρκετοί παράγοντες που
πρέπει να ληφθούν υπ' όψη κατά το
σχεδιασμό της επικοινωνίας μεταξύ
εργασιών:
Κόστος επικοινωνίας
Η επικοινωνία
εργασιών σχεδόν πάντα υποκρύπει κάποια
επιβάρυνση.
Δαπανάται υπολογιστικός
χρόνος και καταλαμβάνονται πόροι οι
οποίοι θα μπορούσαν να επιταχύνουν
την επίλυση του προβλήματος.
Συνήθως η επικοινωνία
απαιτεί κάποιου τύπου συχγρονισμό ή
ενταμίευση (buffering) που μπορεί να
προκαλέσει επιβάρυνση ή και καθυστέρηση
λόγω αναμονής.
Αν το μέσο επικοινωνίας (δίκτυο,
απομονωτές, μνήμη) έχουν περιορισμένο
εύρος ζώνης, η επικοινωνία μπορεί να
προκαλέσει καθυστερήσεις και σοβαρή
μείωση της απόδοσης της παράλληλης
εφαρμογής.
Αρχική Καθυστέρηση
(Latency) και Εύρος Ζώνης (Bandwidth)
Αρχική καθυστέρηση
είναι ο χρόνος που απαιτείται για την
αποστολή του ελαχίστου (0 bytes) μηνύματος
από την εργασία A στήν εργασία B. Συνήθως
μετράται σε microseconds και είναι περίπου
σταθερό μέγεθος ανά μήνυμα.
Εύρος ζώνης
είναι ο ρυθμός μετάδοσης δεδομένων
από την εργασία Α στην εργασία Β. Συνήθως
μετράται σε megabytes/sec και είναι προφανώς
μέγεθος που μεταβάλλεται (όχι απαραίτητα
γραμμικά) με το μέγεθος του μηνύματος.
Η αποστολή πολλών μικρών μηνυμάτων
προκαλεί τη κυριαρχία της αρχικής
καθυστέρησης στο χρόνο επικοινωνίας.
Έτσι είναι καλό να ομαδοποιούμε τα
πολλά μικρά μηνύματα. Βέβαια, η αποστολή
πολύ μεγάλων μηνυμάτων μπορεί να
προκαλέσει συμφόρηση του μέσου
επικοινωνίας. Για κάθε σύστημα είναι
καλό να καθορίζουμε ένα έυρος αποδεκτών
μεγεθών μηνυμάτων ώστε να ελαχιστοποιούμε
τα κόστη επικοινωνίας.
Ορατότητα επικοινωνίας
Στο Μοντέλο Μεταβίβασης
Μηνυμάτων ηι επικοινωνία είναι ρητή
-μέσω εντολών αποστολής και παραλαβής
μυνημάτων- και βρίσκεται υπό τον έλεγχο
του προγραμματιστή.
Στο Μοντέλο Νημάτων
και γενικότερα στα Μοντέλα Μοιραζόμενης
Μνήμης η επικοινωνία μπορεί να είναι
είτε εννοούμενη-μέσω μηχανισμών
μοιραζόμενων μεταβλητών- είτε ρητή-
μέσω ουρών μηνυμάτων ή διοχετεύσεων,
παραμένει δε υπό τον έλεγχο του
προγραμματιστή.
Σε ορισμένα Μοντέλα (πχ DSM) η
επικοινωνία είναι εννούμενη και
συμβαίνει χωρίς την άμεση παρέμβαση
ή έλεγχο του προγραμματιστή. Το σύστημα
αποφασίζει για την κατανομή και
επικοινωνία των δεδομένων.
Σύγχρονη και
Ασύγχρονη επικοινωνία
Η Σύγχρονη επικοινωνία
απαιτεί κάποιο είδος πρωτοκόλλου
χειραψίας ("handshaking", ACK) μεταξύ των
εργασιών. Αυτό μπορει να υλοποιείται
είτε ρητά από το προγραμματιστή ή από
το σύστημα με ειδικές βιβλιοθήκες.
Η Σύγχρονη επικοινωνία
συνήθως αναφέρεται ως ανασταλτική
(blocking) αφού οι εμπλεκόμενες
εργασίες αναστέλουν κάθε άλλη λειτουργία
μέχρι την ολοκλήρωση της επικοινωνίας.
Η Ασύγχρονη επικοινωνία
δεν απαιτεί επιβεβαίωση μεταξύ των
εμπλεκομένων μερών. Για παράδειγμα η
εργασία Α μπορεί να στείλει μήνυμα
στην εργασία Β και, χωρίς να περιμένει
ACK να συνεχίσει τη λειτουργία της. Η
εργασία Β θα παραλάβει το μήνυμα στο
δικό της χρόνο.
Η Ασύγχρονη επικοινωνία
συνήθως αναφέρεται και ως μη-ανασταλτική
(non-blocking) αφού οι εμπλεκόμενες
εργασίες μπορεί να εκτελούν άλλες
λειτουργίες μέχρι την ολοκλήρωση της
επικοινωνίας.
Το βασικό πλεονέκτημα
της Ασύγχρονης επικοινωνίας είναι η
επικάλυψη επικοινωνίας και υπολογισμού.
Το βασικό μειονέκτημά της είναι η
δυσκολότερη εκσφαλμάτωση των
προγραμμάτων.
Υπάρχει και Ανασταλτική
Ασύγχρονη επικοινωνία, όπου ο αποστολέας
λαμβάνει επιβεβαίωση αποστολής από
το σύστημα εκτέλεσης (ενταμίευση
μηνύματος σε ουρά) και όχι από τον
παραλήπτη. Το σύστημα εκτέλεσης είναι
υπέυθυνο για την ορθή διαχείριση των
ουρών και την σωστή ταύτιση αποστολέα
και παραλήπτη.
Επίσης υπάρχει και Μη-Καθοριστική
Ασύγχρονη επικοινωνία όπου, δεν είναι
απαραίτητο να υπάρξει τελικά παραλήτης
ή αποστολέας για κάποιο μήνυμα, δηλαδή
η επικοινωνία αντιμετωπίζεται ως ένα
πιθανό γεγονός αλλά όχι απαραίτητο να
συμβεί.
Στατική και Δυναμική
Σχεδιασμός Παράλληλων Προγραμμάτων
|
Συγχρονισμός
Τύποι Συγχρονισμού:
Σχεδιασμός Παράλληλων Προγραμμάτων
|
Εξαρτήσεις Δεδομένων
Ορισμοί:
Υπάρχει σειραική
εξάρτηση (dependence) μεταξύ
εντολών ενός προγράμματος όταν η σειρά
εκτέλεσης των εντολών επηρρεάζει το
αποτέλεσμα του προγράμματος.
Η εξάρτηση
δεδομένων (data dependence) προκύπτει
από την πολλαπλή χρήση των ίδιων
μεταβλητών (θέσεων μνήμης) από διαφορετικές
εργασίες.
Οι επαναληπτικές και δομικές
εξαρτήσεις είναι σημαντικές στο
παράλληλο προγραμματισμό αφού επηρρεάζουν
την ορθότητα της εκτέλεσης και αποτελούν
βασικό εμπόδιο για τη παραλληλοποίηση
εφαρμογών.
Παραδείγματα:
Επαναληπτική εξάρτηση
DO 500 J = MYSTART,MYEND
A(J) = A(J-1) * 2.0
500 CONTINUE
|
Η τιμή του A(J-1) πρέπει να είναι γνωστή
πριν υπολογιστεί η τιμή του A(J), άρα
υπάρχει εξάρτηση μεταξύ A(J) και A(J-1).
Αν η εργασία 2 υπολογίζει το A(J) και η
εργασία 1 το A(J-1), ο σωστός υπολογισμός
του A(J) απαιτεί η εργασία 2 να έχει
πρόσβαση στη τιμή του A(J-1) μετά
τον υπολογισμό του. Αυτό σημαίνει:
Σε σύστημα κατανεμημένης
μνήμης: η εργασία 1 υπολογίζει την τιμή
του A(J-1) και την αποστέλει στην εργασία
2. Η εργασία 2 αναμένει να παραλάβει την
τιμή Α(J-1) για να υπολογίσει την τιμή
του Α(J).
Σε σύστημα μοιραζόμενης μνήμης: η
εργασία 1 υπολογίζει την τιμή του A(J-1)
και ενημερώνει (γράφει) τη κατάλληλη
θέση μνήμης. Η εργασία 2 πρέπει να
αναμένει την ενημέρωση της τιμής Α(J-1)
για να υπολογίσει την τιμή του Α(J).
Δομική εξάρτηση
task 1 task 2
------ ------
Push(2) Push(4)
. .
. .
Χ = Pop() Υ = Pop()
|
Σε μια μοιραζόμενη στοίβα δεν μπορούμε
να γνωρίζουμε ούτε τη σειρά εισαγωγής
ούτε τη σειρά εξαγωγής στοιχείων. Ο
μόνος τρόπος είναι να σειριοποιήσουμε
τη διαδικασία, εμποδίζοντας έτσι τον
παραλληλισμό. Η τιμή των X, Y εξαρτάται:
Σε σύστημα κατανεμημένης
μνήμης: από τη σειρά αποστολής/παραλαβής
των μηνυμάτων push και pop προς τη μοιραζόμενη
δομή δεδομένων.
Σε σύστημα μοιραζόμενης μνήμης:
από τη σειρά εγγραφής/ανάγνωσης των
λειτουργιών push και pop στη μοιραζόμενη
δομή δεδομένων.
Αν και όλες οι εξαρτήσεις δεδομένων
είναι σημαντικές αφού καθορίζουν το
σχεδιασμό του παράλληλου προγράμματος,
οι εξαρτήσεις βρόχων (χρονικές) είναι
ιδιαίτερα σημαντικές γιατί αφορούν το
πιο χρονοβόρο τμήμα της εφαρμογής.
Χειρισμός των Εξαρτήσεων:
Σχεδιασμός Παράλληλων Προγραμμάτων
|
Εξισορρόπηση Φορτίου
Η εξισορρόπηση
φορτίου έχει σαν στόχο την όσο το δυνατό
ισομερή κατανομή υπολογιστικού φόρτου
μεταξύ εργασιών ώστε όλες οι
εργασίες να εκτελούν χρήσιμους
υπολογισμούς όλο το χρόνο.
Διαφορετικά, σημαίνει την ελαχιστοποίηση
του άεργου χρόνου (αναστολή, αναμονή)
των εργασιών.
Η εξισορρόπηση φορτίου είναι
σημαντική για λόγους απόδοσης. Για
παράδειγμα, στο παρακάτω σχήμα ένα
φράγμα υποχρεώνει όλες τις εργασίες
να συγχρονιστούν σε ένα χρονικό σημείο.
Η εργασία 3, που έχει το μεγαλύτερο
φορτίο, υποχρεώνει τις υπόλοιπες
εργασίες σε αναμονή, μειώνοντας έτσι
την συνολική απόδοση. Τακ =
Work1+Work2+Work3+Work4, Tπαρ = Work3. Επιτάχυνση
= Τακ/Τπαρ < 4. Κόστος ακ =
Τακ Χ 1, Κόστος παρ = Τπαρ Χ
4. Ωφελιμότητα = Κόστος ακ / Κόστος
παρ = Επιτάχυνση / 4 < 100%
Πώς Επιτυγχάνεται η Εξισορρόπηση
Φορτίου:
Σχεδιασμός Παράλληλων Προγραμμάτων
|
Κοκκιότητα
Λόγος Υπολογισμού / Επικοινωνίας:
Στη παράλληλη
επεξεργασία η κοκκιότητα χρησιμοποιείται
ως ποιοτικό μέτρο του λόγου υπολογισμού
προς επικοινωνία.
Τυπικά έχουμε περιόδους υπολογισμού
που χωρίζονται από περιόδους επικοινωνίας
μέσω συγχρονισμού.
Λεπτομερής (Fine-grain) Παραλληλισμός:
Σχετικά λίγοι
υπολογισμοί μεταξύ διαδοχικών
επικοινωνιών
Μικρός λόγος
υπολογισμού προς επικοινωνία
Ευχερέστερη
εξισορρόπηση φορτίου, η απόδοση
καθορίζεται από την επικοινωνία
Μεγάλη επιβάρυνση
επικοινωνίας, μπορεί η επικοινωνία
και ο συχγρονισμός να κοστίζουν πολύ
περισσότερο από τον υπολογισμό
Απαιτεί υπερταχεία
επικοινωνία και συνήθως εφαρμόζεται
σε αρχιτεκτονικές ειδικού σκοπού
όπου απαιτείται συνεχής ροή δεδομένων
και λύσεις πραγματικού χρόνου (πχ
audio, video streaming, computer graphics, games).
Αδρομερής (Coarse-grain) Παραλληλισμός:
Σχετικά πολλοί
υπολογισμοί μεταξύ διαδοχικών
επικοινωνιών
Μεγάλος λόγος
υπολογισμού προς επικοινωνία
Δυσκολότερη
εξισορρόπηση φορτίου, η απόδοση
καθορίζεται από τον υπολογισμό
Η ευχερέστερη
προσέγγιση στα συνηθισμένα παράλληλα
συστήματα όπου το εύρος ζώνης των
επεξεργαστών είναι κατά τάξεις
μεγέθους μεγαλύτερο του εύρους ζώνης
επικοινωνίας.
Ποιά κοκκιότητα είναι καλύτερη;
Η βέλτιση κοκκιότητα
μιας παράλληλης εφαρμογής εξαρτάται
από το συγκεκριμένο σύστημα όπου
εκτελείται.
Στα περισσότερα
συστήματα γενικού σκοπού η επικοινωνία
έχει πολύ υψηλότερο κόστος από τον
υπολογισμό με αποτέλεσμα την πριμοδότηση
του αδρομερούς παραλληλισμού.
Ο λεπτομερής παραλληλισμός βρίσκει
εφαρμογή κυρίως σε συστήματα ειδικού
σκοπού με επικοινωνία υψηλού εύρους
ζώνης.
|

|
Σχεδιασμός Παράλληλων Προγραμμάτων
|
Είσοδος/'Εξοδος (I/O)
Τα Κακά Νέα:
Γενικά οι λειτουργίες
I/O προκαλούν καθυστερήσεις και θεωρούνται
εμπόδια στο παραλληλισμό.
Υπάρχουν παράλληλα
συστήματα I/O αλλά είναι ανώριμα και όχι
ευρέως διαθέσιμα.
Σε ένα περιβάλλον
που όλες οι εργασίες βλέπουν το ίδιο
χώρο αρχείων, οι παράλληλες εγγραφές
πρέπει αναγκαστικά να κλειδώνονται.
Οι παράλληλες
αναγνώσεις περιορίζονται από το εύρος
ζώνης του συστήματος I/O και τη δυνατότητα
για ταυτόχρονη εξυπηρέτηση πολλαπλών
αιτήσεων.
Ταυτόχρονες λειτουργίες I/O μεγάλου
όγκου που εκτελούνται μέσω δικτύου (πχ
NFS) προκαλούν μεγάλες συμφορήσεις.
Τα Καλά Νέα:
Υπάρχουν μερικά
συστήματα παράλληλης I/O:
GPFS: General Parallel File
System, AIX (IBM)
Lustre: Linux clusters (Cluster
File Systems, Inc.)
PVFS/PVFS2: Parallel Virtual File
System, Linux clusters (Clemson/Argonne/Ohio State/others)
PanFS: Panasas ActiveScale File
System, Linux clusters (Panasas, Inc.)
HP SFS: HP StorageWorks Scalable File Share. Lustre, HP.
To MPI-2 περιλαμβάνει διεπαφή
προγραμματισμού για παράλληλη I/O, με
αρκετές διαθέσιμες υλοποιήσεις.
Μερικές επιλογές:
Αν έχετε πρόσβαση
σε σύστημα παράλληλης Ι/Ο διερευνήστε
το. Αλλιώς διαβάστε παρακάτω..
Μειώστε τις συνολικές
λειτουργίες I/O όσο περισσότερο γίνεται.
Περιορίστε τις
λειτουργίες I/O σε συγκεκριμένα σειραικά
τμήματα του προγράμματος (αρχικοποίηση
και τελική αποθήκευση). Για μεγάλο όγκο
δεδομένων, κάθε εργασία μπορεί να
διαβάζει από αρχείο μόνο στην αρχικοποίηση
και να αποθηκεύει σε αρχείο μόνο στη
τελική φάση.
Για μικρό όγκο
δεδομένων, οι λειτουργίες Ι/Ο μπορεί
να γίνονται από μια εργασία και κατόπιν
να χρησιμοποιύνται παράλληλες
επικοινωνίες για διανομή και συλλογή
προς/από τις άλλες εργασίες.
Για συστήματα
κατανεμημένης μνήμης με μοιραζόμενο
χώρο αρχείων (πχ NFS), όταν υπάρχει μεγάλος
όγκος δεδομένων καλό είναι να
χρησιμοποιούμε λειτουργίες I/O σε τοπικό
χώρο αρχείων. Για παράδειγμα, με χρήση
NFS μπορούμε να μεταφέρουμε τα δεδομένα
από το μοιραζόμενο κατάλογο /home σε
τοπικό κατάλογο /tmp και να συλλέγουμε
τα τελικά αποτελέσματα εκ των υστέρων.
Αν δεν μπορείτε να χρησιμοποιήσετε
τοπικό κατάλογο, τότε ίσως μπορείτε
να χρησιμοποιείσετε στο μοιραζόμενο
κατάλογο διαφορετικά ονόματα αρχείων
για τις λειτουργίες Ι/Ο κάθε εργασίας.
Απόδοση Παράλληλων Προγραμμάτων
|
Όρια και Κόστη Παράλληλου
Προγραμματισμού
Νόμος Amdahl:
Ο
Νόμος του Amdahl υπολογίζει τη μέγιστη
δυνατή επιτάχυνση για μια συγκεκριμένη
εφαρμογή ως εξής: Έστω οτι ο ακολουθιακός
κώδικας αποτελείται από δύο τμήματα,
ένα που μπορεί να παραλληλοποιηθεί και
ένα που δεν μπορεί. Άρα, Tακ
= 1 = P + (1 - P). Προσοχή: το P δεν αναφέρεται
σε αριθμό γραμμών αλλά σε ποσοστό επί
του μοναδιαίου χρόνου εκτέλεσης, δηλαδή
στο ποσοστό χρόνου εκτέλεσης που
αντιστοιχεί στα θερμά σημεία του
προγράμματος. Έστω επίσης οτι ο
παραλληλοποιημένος κώδικας εκτελείται
σε σύστημα με N επεξεργαστές, και έχει
χρόνο εκτέλεσης Tπαρ = P/Ν+ (1 - P). Η
μέγιστη αναμενόμενη επιτάχυνση είναι:
Τακ P + (1 - P) 1 1
Smax = ------- = ------------------ = ------------ και -------- αν Ν -> απειρο
Τπαρ P/Ν + (1 - P) P/Ν + (1 - P) 1 - P
|
Αν δεν υπάρχει παραλληλοποίηση,
τότε P = 0 και Smax = 1 (καμμία επιτάχυνση).
Αν υπάρχει πλήρης παραλληλοποίηση,
τότε P = 1 και η μέγιστη επιτάχυνση S
μπορεί να αυξηθεί αυθαίρετα, ανάλογα
με την υλοποίηση. Αν τα θερμά σημεία
αντιστοιχούν στο 50% του χρόνου εκτέλεσης,
τότε P = 0.5 και η μέγιστη επιτάχυνση είναι
2/(Ν+1) < 2!
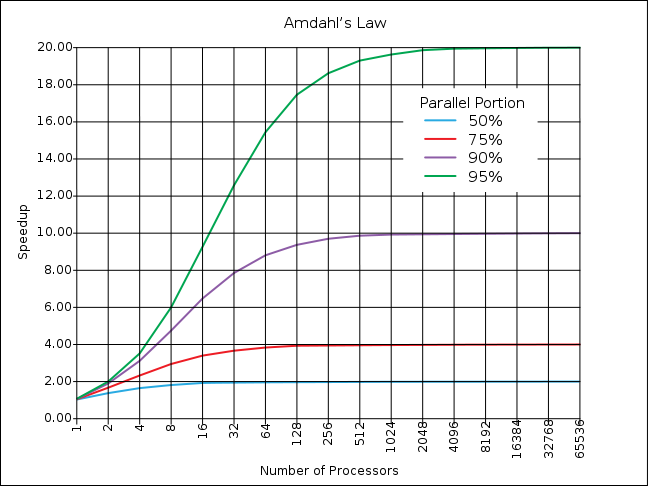
Γρήγορα γίνονται φανερά τα όρια
στη κλιμάκωση του παραλληλισμού. Στην
εικόνα φαίνονται οι μέγιστες επιταχύνσεις
για διάφορα P και Ν. Είναι προφανές
οτι για P < 0.75 η χρήση άνω των 16 ή 32
επεξεργαστών είναι ανώφελη, ενώ η
μέγιστη επιτάχυνση περιορίζεται στο
8. Αντίστοιχα για P < 0.90 χρειαζόμαστε
περίπου 128 επεξεργαστές για να επιτύχουμε
επιτάχυνση 16.
Όμως αυτή το εκ πρώτης όψεως
αποθαρρυντικό συμπέρασμα δε λαμβάνει
υπ' όψη του το γεγονός οτι οι ενδιαφέρουσες
εφαρμογές έχουν συνήθως θερμά σημεία
των οποίων το ποσοστό υπερβαίνει το
0.8 και αυτό ο ποσοστό αυξάνει με το
μέγεθος του προβλήματος. Για παράδειγμα
ένας πολλαπλασιαμός πινάκων έχει Τακ
= P + (1 -P) = Μ3 υπολογισμό + 3Μ2
Ι/Ο όπου ΜΧΜ το μέγεθος των πινάκων. Από
αυτά αν θεωρήσουμε το Ι/Ο τμήμα ως
ακολουθιακό και τον υπολογισμό ως
παραλληλοποιήσιμο, τότε για διάφορα Μ
έχουμε:
Μ = 10^3 P = 10^9 ή 99.70% (1 - P) = 3*10^6 ή 0.030%
Μ = 10^4 P = 10^12 ή 99.97% (1 - P) = 3*10^8 ή 0.003%
Μ = 10^6 P = 10^18 ή 99.99% (1 - P) = 3*10^12 ή 0.001%
Τα προβλήματα των οποίων το P αυξάνεται
μαζί με το μέγεθός τους είναι περισσότερο
κλιμακώσιμα (scalable) από
οτι προβλήματα με σταθερό P (Νόμος
του Gustafson ή isoefficiency). Ο Νόμος
Gustafson αναδιατυπώνει το Νόμο Amdahl ως εξής.
Για τις ίδιες παραδοχές όπως προηγούμενα,
έστω Τπαρ = a + b = 1, όπου a το μη
παραλληλοποιήσιμο τμήμα και b το
παραλληλοποιήσιμο. Τότε έχουμε Tακ
= a + b * N και θέτουμε g = a / (a + b) το ποσοστό
μη παραλληποιούμενου τμήματος ως προς
το σύνολο. Όσο το μέγεθος του πρόβληματος
μεγαλώνει το g τείνει προς το μηδέν (όπως
στο προηγούμενο παράδειγμα. ΄Ετσι η
μέγιστη επιτάχυνση τείνει στο N.
Τακ a + b * N
Smax = ------- = ----------- = g + N * ( 1 - g ), και Smax --> N αν g --> 0
Τπαρ a + b
|
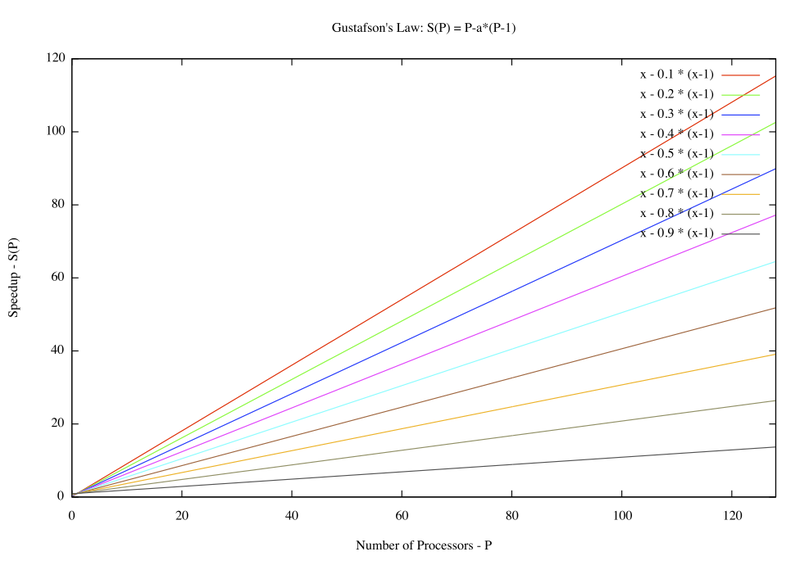
Τα προβλήματα των
οποίων το P αυξάνεται μαζί με το μέγεθός
τους είναι περισσότερο κλιμακώσιμα
(scalable) από οτι προβλήματα με
σταθερό P.
Από την άλλη πλευρά ο νόμος του
Amdahl μεροληπτεί υπέρ του παραλληλισμού
γιατί δεν λαμβάνει υπ' όψη του την
επιβάρυνση της παράλληλης εφαρμογής
που προκύπτει από τη διαχείριση των
εργασιών και των δεδομένων.
Πολυπλοκότητα:
Γενικά οι παράλληλες
εφαρμογές είναι αρκετά πιο σύνθετες
από τις αντίστοιχες ακολουθιακές. Όχι
μόνο πρέπει να παρακολουθούμε πολλαπλές
ροές εντολών που εκτελούνται ταυτόχρονα
αλλά και πολλαπλές ομάδες δεδομένων
που υφίστανται ταυτόχρονη επεξεργασία.
Το κόστος αυτής της
πολυπλοκότητας είναι εμφανές σε σχεδόν
όλες τις φάσεις ανάπτυξης της εφαρμογής:
Σχεδιασμό
Συγγραφή
Εκσφαλμάτωση
Βελτιστοποίηση
Συντήρηση
Η τήρηση καλών πρακτικών ανάπτυξης
λογισμικού είναι ιδιαίτερα σημαντική
- ιδιαίτερα αν τη λογισμικό που θα
αναπτυχθεί θα χρησιμοποιηθεί από άλλους
χρήστες.
Φορητότητα:
Χάρη στη προτυποποίηση
αρκετών APIs, όπως το MPI, POSIX, OpenMP και HPF, η
φορητότητα των παράλληλων εφαρμογών
είναι πολύ μεγαλύτερη από οτι πριν μια
δεκαετία. Όμως...
Όλα τα συνήθη
προβλήματα συμβατότητας των ακολουθιακών
εφαρμογών ισχύουν και εδώ. Για παράδειγμα,
διάφοροι κατασκευαστές προσφέρουν
"βελτιωμένες" βιβλιοθήκες με
ειδικές συναρτήσεις, η χρήση των οποίων
μειώνει τη φορητότητα.
Αν και υπάρχει
προτυποποίηση των APIs, μπορεί υπάρχουν
διαφορές στην υλοποίηση οι οποίες
επηρρεάζουν την απόδοση ώστε να
απαιτείται προσαρμογή του κώδικα.
Τα λειτουργικά
συστήματα και τα συστήματα εκτέλεσης
επηρρεάζουν σημαντικά την φορητότητα.
Η αρχιτεκτονική είναι ο βασικότερος
περιορισμός στη φορητότητα.
Απαιτήσεις σε Πόρους:
Ο πρωταρχικός στόχος
της παράλληλης επεξαργασίας είναι η
μείωση του χρόνου εκτέλεσης (wall
clock time) μιας εφαρμογής. Όμως αυτό
μπορεί να σημαίνει τη συνολική χρήση
περισσότερου χρόνου επεξεργασίας (CPU
time). Για παράδειγμα η εκτέλεση μιας
ακολουθιακής εφαρμογής μπορεί να
απαιτεί 4 ώρες σε ένα επεξεργαστή ενώ
μιας παράλληλης 1.5 ώρα σε 4 επεξεργαστές.
To wall clock time μειώθηκε από 4 σε 1.5 αλλά το
CPU time αυξήθηκε από 4 σε 6.
Οι απαιτήσεις σε
μνήμη μπορεί επίσης να αυξηθούν, λόγω
της ανάγκης για δημιουργία αντιγράφων
ορισμένων δεδομένων για κάθε παράλληλη
εργασία, καθώς επίσης και για την χρήση
των βιβλιοθηκών και του συστήματος
εκτέλεσης.
Ειδικά για παράλληλες εφαρμογές
σχετικά μικρού μεγέθους, είναι αρκετά
συνηθισμένο να έχουμε μείωση αντί
αύτη αύξηση της απόδοσης, σε σύγκριση
με την ακολουθιακή εφαρμογή. Η επιβάρυνση
δημιουργίας, διαχείρισης και συχγρονισμού
εργασιών, καθώς και η διανομή, επικοινωνία
και συλλογή δεδομένων, επιφέρει
μεγαλύτερη καθυστέρηση στην παράλληλη
εφαρμογή από το κέρδος της όποιας
επιτάχυνσης.
Κλιμάκωση:
Η δυνατότητα επιτυχούς
κλιμάκωσης μιας παράλληλης εφαρμογής
εξαρτάται από αρκετούς παράγοντες. Η
απλή πρόσθεση περισσότερων επεξεργαστών
συνήθως δεν αρκεί, εκτός ίσως από τις
περιπτώσεις φυσικού παραλληλισμού.
Συνήθως οι παράλληλοι
αλγόριθμοι έχουν ορισμένα όρια στη
κλιμάκωση που επιτρέπουν. Επομένως,
αρχικά η πρόσθεση νέων επεξεργαστών
παρουσιάζει σημαντική βελτίωση της
απόδοσης, ενώ στη συνέχεια οι επιπλέον
επεξαργαστές δεν αποδίδουν τα αναμενόμενα
και σταδιακά μπορεί να έχουμε μείωση
της απόδοσης. Οι συνηθέστεροι λόγοι
είναι τρείς:
υπερβολική αύξηση
της διαχειριστικής επιβάρυνσης της
εφαρμογής
υπερβολική αύξηση
της επικοινωνίας δεδομένων ή συγχρονισμού
υπερβολική μείωση
της κοκκότητας, δηλαδή του υπολογισμού
ανά επεξεργαστή
Η αρχιτεκτονική και
το υλικό παίζουν σημαντικό ρόλο στη
κλιμάκωση. Παραδείγματα:
Το εύρος ζώνης του
διαύλου μνήμης και τα επίπεδα/το μέγεθος
της κρυφής μνήμης
Το εύρος ζώνης του
συστήματος επικοινωνίας
Το μέγεθος της
διαθέσιμης μνήμης, τοπικής ή και
μοιραζόμενης
Τεχνολογία και
ταχύτητα επεξεργαστών
Η υλοποίηση των διαφόρων APIs επίσης
μπορεί να επηρρεάσει την κλιμάκωση
λόγω περιορισμών που επιβάλλονται.
Για παραπέρα ανάλυση της
απόδοσης αλλά και για τη πειραματική
μέτρηση της απόδοσης των παράλληλων
προγραμμάτων βλ. το βιβλίο του Ian Foster
Designing and
Building Parallel Programs. όπουθ υπάρχει και
σχετική ενότητα μεταφρασμένη στα
Ελληνικά.
Παραδείγματα Παράλληλης Επεξεργασίας
|
Επεξεργασία Πινάκων
Αυτό το παράδειγμα
αφορά υπολογισμούς σε 2-διάστατο
πίνακα, με τους υπολογισμούς κάθε
στοιχείου να είναι ανεξάρτητοι μεταξύ
τους.
Το ακολουθιακό
πρόγραμμα υπολογίζει τη τιμή κάθε
στοιχείου του πίνακα με τη σειρά (κατά
γραμμή, κατά στήλη).
Τυπικός ακολουθιακός
κώδικας:
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
a(i,j) = fcn(i,j)
|
Αφού οι υπολογισμοί
είναι ανεξάρτητοι μεταξύ τους η
εφαρμογή φυσικού παραλληλισμού είναι
προφανής.
Η βέλτιστη
κοκκιότητα σχετίζεται με την
πολυπλοκότητα του υπολογισμού fcn(i,j)
καθώς και με την διαθέσιμη αρχιτεκτονική
(ισχύς επεξεργαστή, εύρος ζώνης μνήμης,
εύρος ζώνης επικοινωνίας).
Η εξισορρόπηση
φορτίου σχετίζεται με τη σχετική ισχύ
των διαθέσιμων επεξεργαστών και με
τον ομοιογενή ή μη υπολογισμό της
fcn(i,j) για διαφορετικά i,j.
|
|
Επεξεργασία Πινάκων
Παράλληλη
Λύση 1: Στατική Κατανομή
Τα στοιχεία του
πίνακα ανατίθενται στις παράλληλες
εργασίες έτσι ώστε κάθε εργασία
επεξεργάζεται ένα τμήμα του πίνακα.
Η ανάθεση μπορεί να είναι λογική,
π.χ. οι δείκτες των for λαμβάνουν
διαφορετικές τιμές ανά εργασία
(μοιραζόμενη μνήμη), ή φυσική,
π.χ. τα τμήματα του πίνακα τοποθετούνται
σε τοπική μνήμη που αντιστοιχεί σε
κάθε διεργασία (κατανεμημένη μνήμη).
Αφού οι υπολογισμοί
είνα ανεξάρτητοι μεταξύ τους δεν
απαιτείται επικοινωνία μεταξύ τωνε
εργασιών.
Τα σχήματα
επιμερισμού δεδομένων μπορεί να είναι
πολλά και σχετίζονται με διάφορα
κριτήρια, π.χ. βελτιστοποίηση
κοκκιότητας, εξισορρόπηση φορτίου,
βελτιστοποίηση επικοινωνίας ή απόδοσης
κρυφής μνήμης. Επίσης η γλώσσα
προγραμματισμού και οι επιλογές που
παρέχει το API παίζουν σημαντικό ρόλο.
Στην ενότητα Επιμερισμού
Δεδομένων εμφανίζονται διάφορες
δυνατότητες.
Μετά τον επιμερισμό
των δεδομένων κάθε εργασία επεξεργάζεται
τα στοιχεία που της αναλογούν. Για
παράδειγμα (με βάση το σχήμα):
for (j = myfisrtcolumn; j <= mylastcolumn; j++)
for (i = 0; i < n; i++)
a(i,j) = fcn(i,j)
|
Αυτό που ουσιαστικά
αλλάζει είναι η σχετική σειρά των
επαναλήψεων (i,j) και οι δείκτες της
εξωτερικής επανάληψης.
|
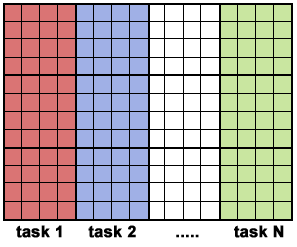
|
Μια πιθανή λύση:
Υλοποίηση του μοντέλου
SPMD.
Η εργασία Συντονιστής
(Master) αρχικοποιεί τον πίνακα, διανέμει
δεδομένα στις εργασίες Εργαζόμενους
(Workers) και μετά τους υπολογισμούς
συλλέγει τα αποτελέσματα.
Οι Εργαζόμενοι
παραλαμβάνουν δεδομένα, εκτελούν
υπολογισμούς και στέλνουν δεδομένα
στον Συντονιστή.
Ο επιμερισμός
δεδομένων ακολουθεί το σχήμα που
παρουσιάστηκε προηγούμενα.
Στο ψευδοκώδικα που ακολουθεί το
κόκκινο υπογραμμίζει
τις αλλαγές της παραλληλοποίησης.
-
if ( I am MASTER ) {
initialize the array
send each WORKER info on part of array it owns
send each WORKER its portion of initial array
receive from each WORKER results
}
else { // I am a WORKER
receive from MASTER info on part of array I own
receive from MASTER my portion of initial array
# calculate my portion of array
for (j = myfirstcolumn; j <= mylastcolumn; j++)
for (i = 0; i < n; i++)
a(i,j) = fcn(i,j)
send MASTER results
}
|
Επεξεργασία Πινάκων
Παράλληλη
Λύση 2: Δυναμική Κατανομή
Η προηγούμενη λύση
χρησιμοποιεί στατική κατανομή φορτίου:
Κάθε εργασία
αναλαμβάνει σταθερό, προκαθορισμένο
μέρος του συνολικού υπολογισμού
Αν το σύστημα είναι ετερογενές ή
αν οι υπολογισμοί εξαρτώνται από τα
δεδομένα μπορεί να υπάρχει σημαντική
ανισορροπία στο υπολογιστικό φορτίο
των εργασιών.
Η στατική κατανομή
φορτίου δεν προκαλεί προβλήματα όταν
το σύστημα είναι ομογενές και οι
υπολογισμοί σχεδόν ταυτόσημοι για όλα
τα δεδομένα.
Αν δεν ισχύουν τα παραπάνω τότε η
λύση είναι η δυναμική κατανομή φορτίου.
Μια πιθανή λύση:
Πάλι χρησιμοποιούνται δύο τύποι
εργασιών:
Συντονιστής:
Διατηρεί τη λίστα
από τμήματα υπολογισμού (jobs), εδώ
θεωρούμαι ως τμήμα τον υπολογισμό ενός
στοιχείου
Στέλνει στους
Εργαζόμενους τμήματα υπολογισμού,
όταν απαιτούνται
Συλλέγει αποτελέσματα
από τους Εργαζόμενους
Η διαδικασία επαναλαμβάνεται μέχρι
να αδειάσει η λίστα οπότε ενημεώνονται
σχετικά οι Εργαζόμενοι
Εργαζόμενοι:
Λαμβάνει ένα τμήμα
υπολογισμού από τον Συντονιστή
Εκτελεί το τμήμα
υπολογισμού
Στέλνει τα αποτελέσμτα
στον Συντονιστή
Η διαδικασία επαναλαμβάνεται μέχρι
να ειδοποιηθούν από τον Συντονιστή
οτι η λίστα άδειασε
Οι Εργαζόμενοι δεν
γνωρίζουν εκ των προτέρων ποιά τμήματα
του υπολογιστικού φορτίου θα αναλάβει.
Η δυναμική κατανομή
φορτίου συμβαίνει κατά την εκτέλεση:
οι ταχύτεροι Εργαζόμενοι θ αναλάβουν
περισσότερα υπολογιστικά τμήματα.
Στο ψευδοκώδικα που ακολουθεί το
κόκκινο υπογραμμίζει
τις αλλαγές της παραλληλοποίησης.
-
if ( I am MASTER ) {
do {
send to WORKER next job
receive results from WORKER
} while ( there are more jobs )
send to WORKER no more jobs
}
else { // I am WORKER
do {
receive from MASTER next job
calculate array element: a(i,j) = fcn(i,j)
send results to MASTER
} while ( MASTER says no more jobs )
}
|
Συζήτηση:
Στη συγκεκριμένη
λύση η κοκκιότητα είναι εντελώς
λεπτομερής, αφού το υπολογιστικό τμήμα
είναι το μικρότερο δυνατό.
Η διαχείριση τόσο
μικρών εργασιών αυξάνει σημαντικά την
επιβάρυνση επιοινωνίας. Η εξισορρόπηση
φορτίου αντισταθμίζεται από την άυξηση
του χρόνου επικοινωνίας.
Η βέλτιστη κοκκιότητα εξαρτάται
από την εφαρμογή και το σύστημα. Επίσης,
θα μπορούσε να επιλεγεί μια ημι-στατική
κατανομή φορτίου, όπου εκτιμάται εκ
των προτέρων ποιό τμήμα του υπολογιστικού
φορτίου μπορεί να λάβει κάθε εργασία.
Παραδείγματα Παράλληλης Επεξεργασίας
|
Υπολογισμός π
Ο υπολογισμός
του π μπορεί να γίνει με πολλούς
τρόπους. Εδώ εφαρμόζεται η μέθοδος
Monte Carlo
Εγγράφουμε ένα
κύκλο σε ένα τετράγωνο
Παράγουμε τυχαία
σημεία μέσα στο τετράγωνο
Μετρούμε πόσα
από αυτά τα σημεία βρίσκονται μέσα
και στο κύκλο
Έστω r ο λόγος του
πλήθους των σημείων μέσα στο κύκλο
προς το σύνολο των σημείων
π ~ 4 r
Ο υπολογισμός
είναι ακριβής για μεγάλο αριθμό
σημείων
Ψευδικώδικας της
διαδικασίας:
npoints = 100000
circle_count = 0
for (j = 0; j < npoints; j++) {
generate 2 random numbers between 0 and 1
xcoordinate = random1 ; ycoordinate = random2
if (xcoordinate, ycoordinate) inside circle
then circle_count = circle_count + 1
}
PI = 4.0*circle_count/npoints
|
Το σύνολο σχεδόν
των υπολογισμών εκτελείται μέσα στο
βρόχο.
Παράδειγμα φυσικού
παραλληλισμού
Υπολογιστικά
απαιτητικό
Ελάχιστη επικοινωνία
Ελάχιστη I/O
|
|
Υπολογισμός π
Παράλληλη
Λύση
-
npoints = 10000
circle_count = 0
p = number of tasks
num = npoints/p
do j = 1,num
generate 2 random numbers between 0 and 1
xcoordinate = random1 ; ycoordinate = random2
if (xcoordinate, ycoordinate) inside circle
then circle_count = circle_count + 1
end do
if ( I am MASTER ) {
receive from WORKERS their circle_counts
sum all circle_counts
PI = 4*(all circle_counts)/npoints
} else { // I am WORKER
send to MASTER circle_count
}
|
|
|
Παραδείγματα Παράλληλης Επεξεργασίας
|
Απλή Εξίσωση Θερμότητας
Πολλά προβλήματα
παράλληης επεξεργασίας απαιτούν
επικοινωνία μεταξύ των παραλλήλων
εργασιών. Σε αρκετά από αυτά η
επικοινωνία αφορά σε "γειτονικές"
εργασίες.
Στο παράδειγμα,
η εξίσωση θερμότητας περιγράφει τη
μεταβολή της θερμοκρασία σε μια
τετράγωνη επίπεδη επιφάνεια, σε
συνάρτηση με το χρόνο, με δεδομένη
μια αρχική κατάσταση και τις οριακές
συνθήκες.
Για την αριθμητική
επίλυση της διαφορικής εξίσωσης που
προκύπτει χρησιμοποιείται η τεχνική
της διακριτοποίησης, δηλαδή εξισώσειες
πεπερασμένων διαφορών, όπου κάθε
σημείο του τετραγωνικού πλέγματος
ορίζει μια εξίσωση.
Αρχικές συνθήκες:
Υψηλή θερμοκρασία στο κέντρο και
μηδενική στις τέσσερις κορυφές.
Οριακές συνθήκες:
Η θερμοκρασία στις τέσσερις κορυφές
διατηρείται στο μηδέν.
Ο υπολογισμός για
κάθε σημείο εξαρτάται από τα τέσσερα
γειτονικά του σημεία,.
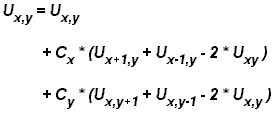
Οι εξισώσεις
διαφορών επιλύονται για διαδοχικά,
μικρά, χρονικά βήματα. Κάθε σημείο
του τετραγώνου επιλύεται για διαδοχικά
χρονικά βήματα, δηλαδή το Uxy στην
αριστερή πλευρά της εξίσωσης είναι
η νέα τιμή (για t+1) ενώ οι τιμές
στην δεξιά πλευρά δίνονται για t.
Επομένως πέρα από την επικοινωνία
απαιτείται και συγχρονισμός της
επαναληπτικής διαδικασίας (έλεγχος
για σύγκλιση και ενημέρωση των παλιών
τιμών στο τέλος κάθε επανάληψης).
Ένα απόσπασμα
ακολουθιακού κώδικα δίνεται παρακάτω.
Υποθέτουμε την ύπαρξη μιας περιμέτρου
'ακραίων' σημείων με μηδενικές τιμές
για λόγους πληρότητας των εξισώσεων:
-
t = 0
do {
for (iy = 0; i < ny; iy++)
for (ix = 0; i < nx; ix++)
u2(ix, iy) = u1(ix, iy) +
cx * (u1(ix+1,iy) + u1(ix-1,iy) - 2.*u1(ix,iy)) + cy * (u1(ix,iy+1) + u1(ix,iy-1) - 2.*u1(ix,iy))
t++
diff = 0
for (ix = 0; i < nx; ix++)
diff += (u1(ix, iy) - u2(ix, iy)) * (u1(ix, iy) - u2(ix, iy))
for (ix = 0; i < nx; ix++)
u1(ix, iy) = u2(ix, iy))
} while ((diff > error) && (t > max_iter))
|
|
|
Απλή Εξίσωση Θερμότητας
Παράλληλη
Λύση 1: Ανασταλτική Επικοινωνία
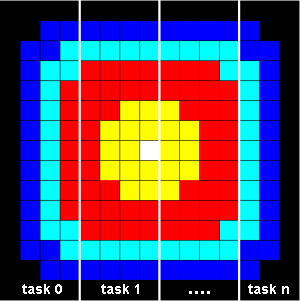 Υλοποίηση
μοντέλου SPMD στη μορφή Συντονιστή -
Εργαζομένων.
Υλοποίηση
μοντέλου SPMD στη μορφή Συντονιστή -
Εργαζομένων.
Το τετραγωνικό πλέγμα
χωρίζεται σε ζώνες (εδώ στήλες) και κάθε
ζώνη ανατίθεται σε μια παράλληλη
εργασία.
Καθορισμός εξαρτήσεων
δεδομένων:
εσωτερικά σημεία
κάθε εργασίας, αυτά που είναι
ανεξάρτητα από τις γειτονικές
οριακά σημεία κάθε εργασίας,
αυτά που απαιτούν επικοινωνία με
γειτονική εργασία.
Ο Συντονιστής στέλνει
αρχικές τιμές, συλλέγει ενημέρωση τιμών
και ελέγχει για σύγκλιση
Οι Εργαζόμενοι
παραλαμβάνουν τα δεδομένα της ζώνης,
υπολογίζουν τις νέες τιμές των στοιχείων
(άρα επικοινωνούν με τους γείτονες),
στέλνουν τα δεδομένα στο Συντονιστή
Στο ψευδοκώδικα που ακολουθεί το
κόκκινο υπογραμμίζει
τις αλλαγές της παραλληλοποίησης.
-
if ( I am MASTER ) {
initialize array
send each WORKER starting info and subarray
do {
gather from all WORKERS convergence data
broadcast to all WORKERS convergence signal
} while ( WORKERS convergence )
receive results from each WORKER
}
else { // I am WORKER
receive from MASTER starting info and subarray
initialize time;
do {
send neighbors my border info
receive from neighbors their border info
calcuate my portion of solution array
update time
determine if my solution has converged
send MASTER convergence data
receive from MASTER convergence signal
update my portion of solution array
} while ( NO convergence )
send MASTER results
}
|
Απλή Εξίσωση Θερμότητας
Παράλληλη
Λύση 2: Μη-Ανασταλτική Επικοινωνία
Στη προηγούμενη λύση
οι εργαζόμενοι αναμένουν την ολοκλήρωση
της επικοινωνίας πριν εκτελέσουν τους
υπολογισμούς κάθε επανάληψης. Δεν
υπάρχει επικάλυψη υπολογισμού και
επικοινωνίας.
Οι γειτονικές εργασίες
ανταλλάσσουν τα οριακά δεδομένα τους
και κατόπιν γίνεται ο υπολογισμός.
Συχνά, ο συνολικός
χρόνος εκτέλεσης μπορεί να μειωθεί με
επικάλυψη επικοινωνίας και υπολογισμού,
με τη χρήση μη-ανασταλτικής επικοινωνίας.
Η μη-ανασταλτική επικοινωνία επιτρέπει
την συνέχιση των υπολογισμών ενώ
εκτελείται επικοινωνία.
Κάθε εργασία μπορεί
να ενημερώσει τα εσωτερικά σημεία εν
αναμονή της ολοκλήρωσης της επικοινωνίας,
και κατόπιν μπορεί να ενημερώσει τα
οριακά σημεία της.
Στο ψευδοκώδικα που ακολουθεί το
κόκκινο υπογραμμίζει
τις αλλαγές της παραλληλοποίησης.
-
if ( I am MASTER ) {
initialize array
send each WORKER starting info and subarray
do {
gather from all WORKERS convergence data
broadcast to all WORKERS convergence signal
} while ( WORKERS convergence )
receive results from each WORKER
}
else { // I am WORKER
receive from MASTER starting info and subarray
initialize time;
do {
non-blocking send neighbors my border info
non-blocking receive neighbors border info
calculate interior of my portion of solution array
wait for non-blocking communication complete
calculate border of my portion of solution array
update time
determine if my solution has converged
send MASTER convergence data
receive from MASTER convergence signal
update my portion of solution array
} while ( NO convergence )
send MASTER results
}
|
Παραδείγματα Παράλληλης Επεξεργασίας
|
Μονο-Διάστατη Εξίσωση Κύματος
Υπολογισμός του
πλάτους κύματος κατά μήκος ομοιογενος
ταλαντούμενης χορδής, σε συνάρτηση με
το χρόνο.
Ο υπολογισμός
ακολουθεί το μοντέλο της διακριτοποίησης
στο χώρο και στο χρόνο. Εδώ ο χώρος έχει
μια διάσταση:
η ποσότητα προς
υπολογισμό είναι το πλάτος κύματος A
στον άξονα y
η χορδή εκτείνεται
στον άξονα x και διακριτοποιείται σε
σημεία (δείκτης i)
το πλάτος κύματος A σε κάθε σημείο
i υπολογίζεται επαναληπτικά σε χρονικά
διαστήματα t.
Η μονο-διάστατη εξίσωση διαφορών
έχει τη μορφή:
A(i,t+1) = (2.0 * A(i,t)) - A(i,t-1)
+ (c * (A(i-1,t) - (2.0 * A(i,t)) + A(i+1,t)))
οπου c είναι μια σταθερά.
Το πλάτος κύματος (t+1) εξαρτάται από
τα δύο προηγούμενα βήματα (t, t-1) και τα
γειτονικά σημεία (i-1, i+1). Οι εξαρτήσεις
δεδομένων σημαίνουν οτι θα υπάρχει
επικοινωνία και συγχρονισμός.
Μονο-Διάστατη Εξίσωση Κύματος
Παράλληλη Λύση
Υλοποίηση μοντέλου
SPMD στη μορφή Συντονιστής - Εργαζόμενοι.
Τα στοιχεία της
χορδής επιμερίζονται τμήματα και
κατανέμονται στις παράλληλες εργασίες.
Δεν απαιτείται
εξισσορόπηση φορτίου, αφού όλα τα σημεία
υφίστανται την ίδια επεξαργασία.
Επικοινωνία απαιτείται μόνο μεταξύ
των οριακών σημείων των τμημάτων κάθε
εργασίας. Μεγάλα τμήματα σημαίνει λίγες
εργασίες με πολύ υπολογισμό και
περιορισμένη επικοινωνία. Μικρά τμήμα
σημαίνει πολλές εργασίες με λίγο
υπολογισμό και περισσότερη επικοινωνία.
-
find out number of tasks and task identities
#Identify left and right neighbors
left_neighbor = mytaskid - 1
right_neighbor = mytaskid +1
if mytaskid = first then left_neigbor = last
if mytaskid = last then right_neighbor = first
if ( I am MASTER ) {
initialize array
send each WORKER starting info and subarray
} else { // I am WORKER
receive starting info and subarray from MASTER
}
#Update values for each point along string
#In this example the master participates in calculations
for (t = 0; t < nsteps; t++) {
send left endpoint to left neighbor
receive left endpoint from right neighbor
send right endpoint to right neighbor
receive right endpoint from left neighbor
#Update points along line
for (i = 0; i < npoints; i++)
newval(i) = (2.0 * values(i)) - oldval(i) + (c * (values(i-1) - (2.0 * values(i)) + values(i+1)))
}
#Collect results and write to file
if ( I am MASTER ) {
receive results from each WORKER
write results to file
} else { // I am WORKER
send results to MASTER
}
|
Περισσότερα παραδείγματα αναλύονται
στο σύνδεσμο Τεχνικές
Παράλληλου Προγραμματισμού.
Tέλος.
Αναφορές και Περισσότερες Πληροφορίες
|
Το αρχικό κείμενο
είναι του Blaise Barney,
lawrence Livermore Laboratory, USA. Επίσης χρησιμοποιήθηκε
υλικό από το κεφ. 8 του βιβλίου του Α.S.
Tanenbaum "Structured Computer Organization, 5e" καθώς
και υλικό από τη Wikipedia και το Διαδίκτυο.
Η μετάφραση, καθώς και οι προσαρμογές
και τροποποιήσεις οφείλονται στο Kώστα
Μαργαρίτη, Πανεπιστήμιο Μακεδονίας.
Μια αναζήτηση στον
ιστό με όρους όπως parallel processing / computing /
programming δίνει πολλές πληροφορίες. Επίσης
η Wikipedia είναι πολύ καλό σημείο εκκίνησης.
Στo http://www.it.uom.gr
επίσης μπορεί να βρεθεί αρκετό
εκπαιδευτικό υλικό .